导读
当前用户界面理解存在的问题:
-
综合性理解挑战:信息图表和用户界面(UI)在视觉和语义上的复杂性,需要一个统一的模型来理解、推理和交互。
-
跨媒体理解:需要处理包括图表、插图、地图、表格、文档布局等在内的多种视觉和文本元素。
-
丰富的用户交互:在数字时代,移动和桌面 UI 需要提供丰富和交互性强的用户体验。
针对以上情况,本文提出的创新点:
-
视觉-语言模型(VLM):提出了 ScreenAI,结合了 PaLI 架构和 Pix2struct 的灵活 patching 机制,将视觉任务转化为(文本,图像)到文本的问题
-
自动数据生成:利用大型语言模型(LLMs)和新的 UI 表示,实现了大规模自动生成训练数据。
-
预训练和微调任务混合:定义了一系列预训练和微调任务,这些任务覆盖了 UI 和信息图表理解的广泛领域。
-
论文名称:ScreenAI: A Vision-Language Model for UI and Infographics Understanding
-
论文地址:https://arxiv.org/pdf/2402.04615
-
代码:无
Introduction
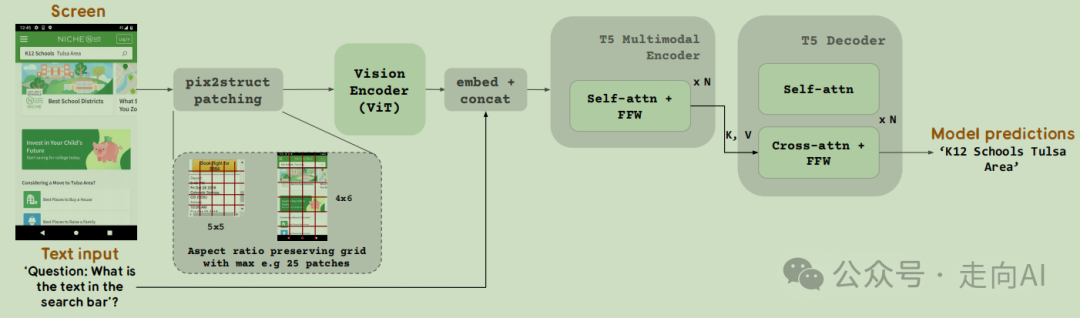
# 模型架构
ScreenAI 的模型架构受到 PaLI 系列模型的启发,并借鉴了 Pix2Struct 中的技术,允许根据输入图像的形状和预定义的最大 patch 数量,拥有任意网格形状的图像 patches,从而适应各种形状的输入图像。
这种策略使得模型能够处理不同格式和纵横比的输入图像,无需对图像进行填充或拉伸到固定形状,增强了模型处理移动(例如纵向)和桌面(例如横向)图像格式的多样性。
我们训练了三种不同大小的模型,分别包含6.7亿、20亿和50亿参数
# 数据生成pipeline
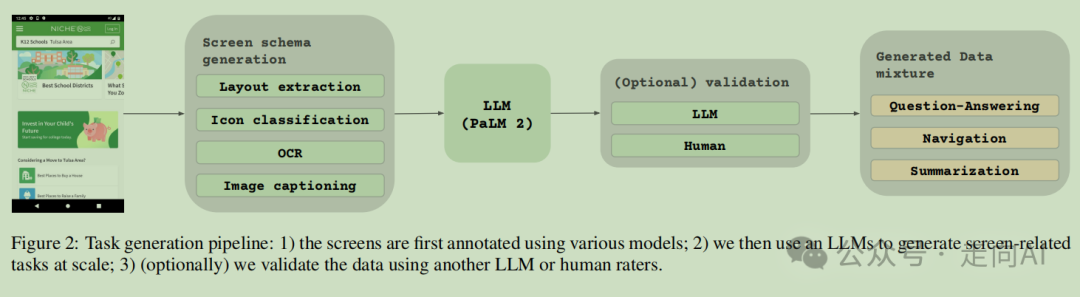
我们模型开发阶段的预训练部分严重依赖于访问广泛和多样化的数据集。鉴于手动标注如此庞大的数据集是不切实际的,我们的策略集中在自动数据生成上。这种方法利用专门的小型模型,每个模型都擅长以高效和高度准确的标签生成数据。Google公开了标注数据:https://github.com/google-research-datasets/screen_annotation
为了在我们的预训练数据中注入更大的多样性,我们利用了大型语言模型(LLMs)的能力,特别是 PaLM 2-S 来分两个阶段生成问答对,这种方法在下图中进行了描述,它使我们能够创建各种合成但现实的任务,显著增强了我们预训练数据集的深度和广度。通过利用这些模型的自然语言处理能力,结合结构化的屏幕架构,我们可以模拟广泛的用户交互和场景。
# 训练任务
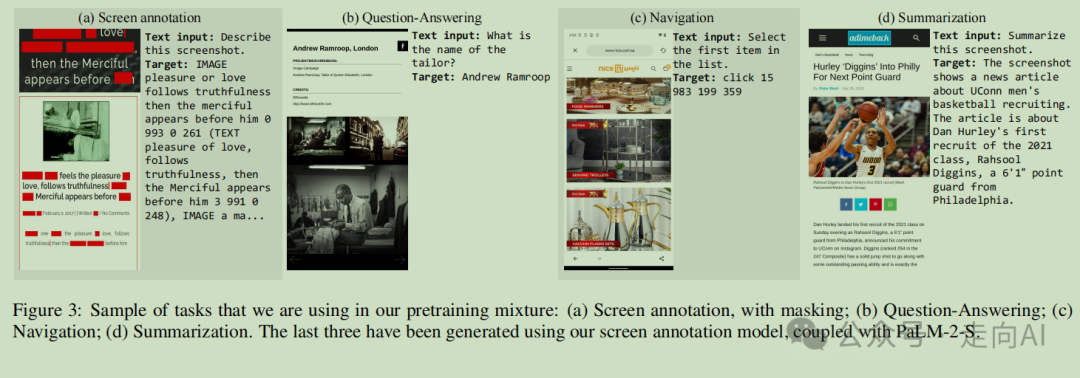
我们为模型的预训练选择的任务在图 3 中各有说明,旨在涵盖广泛的技能和场景,赋予我们的模型多样化的实际应用能力。
-
屏幕标注:模型的任务是检测和识别屏幕上存在的用户界面元素。这包括执行光学字符识别(OCR)和图像字幕以理解和解释文本和非文本内容。为了增强模型的上下文理解能力,一些文本元素被故意遮蔽,鼓励模型根据周围上下文和布局推断信息。
-
屏幕问答:在这个任务中,模型被要求回答与用户界面和计算机生成图像(如信息图表)相关的问题。经过初步实验,我们发现在算术、计数、理解包含复杂信息图表的图像等属性上存在性能差距。为了增强模型的能力,我们创建了专门针对这些差距的数据,例如涉及计数、算术运算和包含信息图表的复杂数据的问答。为了更好地理解图表示例,我们包括了大量的图表到表格转换示例
-
屏幕导航:这个任务涉及解释导航指令(例如,“返回”)并识别要交互的适当用户界面元素。预期的输出是目标元素的边界框坐标,范围在 0 到 999 之间,展示了模型准确理解用户意图并通过界面导航的能力。
-
屏幕摘要:模型的任务是用一两句话简洁地总结屏幕内容。这个任务评估了模型提炼和描述屏幕内容本质的能力。为确保全面训练,能够适应不同的纵横比,每个任务都以多种格式(移动和桌面)提供,并包括几种纵横比。
我们在微调期间使用多种任务和基准测试来评估我们模型的质量。这些基准测试在表 3 中进行了总结:
Experiments
实验设置:在微调阶段,我们将 ViT 编码器保持冻结状态,只微调语言模型。bs设为 512,输入序列长度为 128,输出序列长度根据各个任务的不同而变化。当使用 OCR 作为额外输入进行微调时,会相应增加输入序列长度。除非另有说明,所有实验都在 5B 模型上运行。
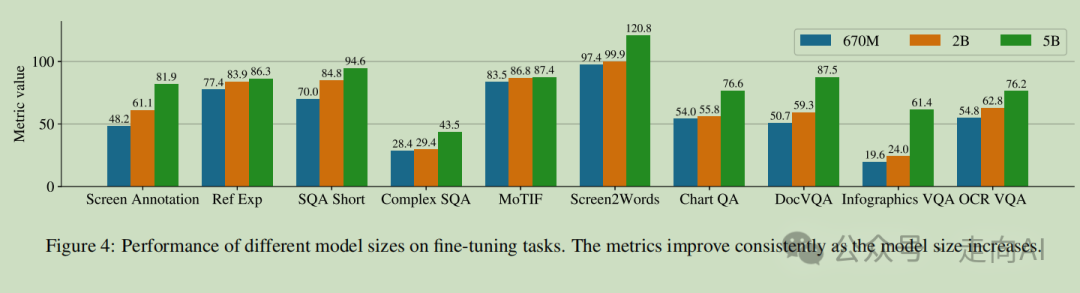
# 实验结果
Analysis
根据实验得到的结论:
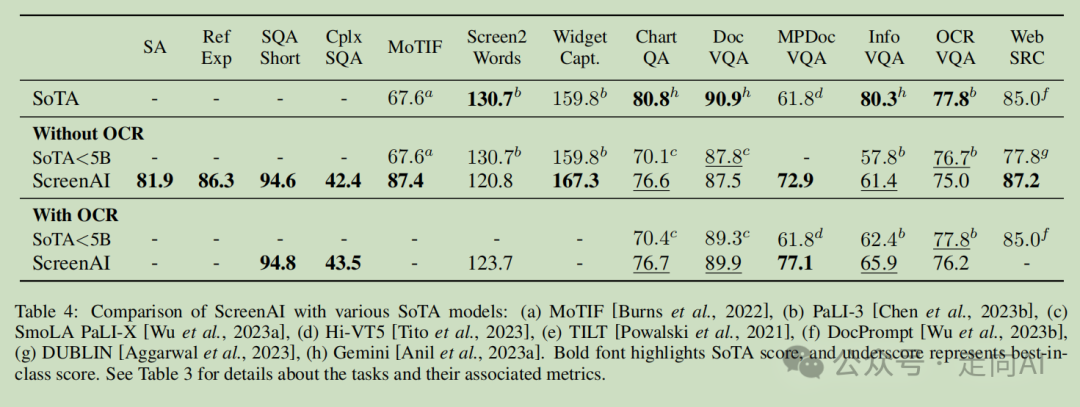
1.对于问答任务,添加 OCR 可以提升性能(例如,在复杂屏幕 QA、MPDocVQA 和 InfoVQA 上高达 4.5%)。然而,使用 OCR 意味着输入长度略增,因此导致整体训练变慢。同时,它还要求在推理时有 OCR 结果可用。
2. 在所有任务中,增大模型大小可以提高性能,且在最大规模上改进尚未饱和。我们注意到对于需要更复杂的视觉-文本和算术推理的任务,例如 InfoVQA、ChartQA 和复杂屏幕 QA,2B 和 5B 模型之间的改进比 670M 和 2B 模型之间的改进要大得多。
3. 在预训练数据中添加 LLM 生成的数据将综合得分提高了 4.6 个百分点。
相比苹果的 Ferret-UI,谷歌的 ScreenAI不仅关注UI屏幕理解,还加入了图表文档等场景的理解。从原理上看,我更喜欢ScreenAI的数据处理流程,而且在screen2words和widget caption这两个任务上也是ScreenAI指标更高。
另外iphone和安卓两大源头不约而同推出基于MLLM的屏幕理解论文,代表了移动设备屏幕理解技术的最新进展,也代表了多模态大模型落地的方向,即与手机、PC相结合,推出AI手机和AI PC,这也是当前产业界的热点,因为:
-
智能交互提升技术融合:Ferret-UI 和 ScreenAI 的出现进一步证明了 AI 技术与移动设备的紧密结合,推动了人机交互的新发展。这些模型通过提高对 UI 元素的理解能力,使得 AI 手机 能够提供更智能、更直观的交互体验。
-
辅助功能扩展:对于有特殊需求的用户,如视觉障碍人士,这些模型可以帮助 AI 手机提供更精准的辅助功能,提高设备的可访问性。
-
个性化服务:随着屏幕理解能力的提升,AI 手机能够更好地学习用户行为和偏好,为用户提供更加个性化的服务和推荐。