

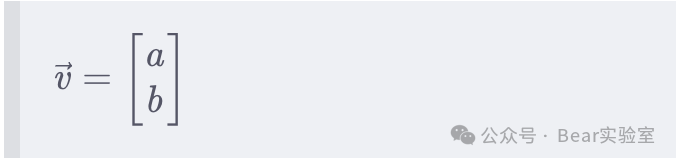
-
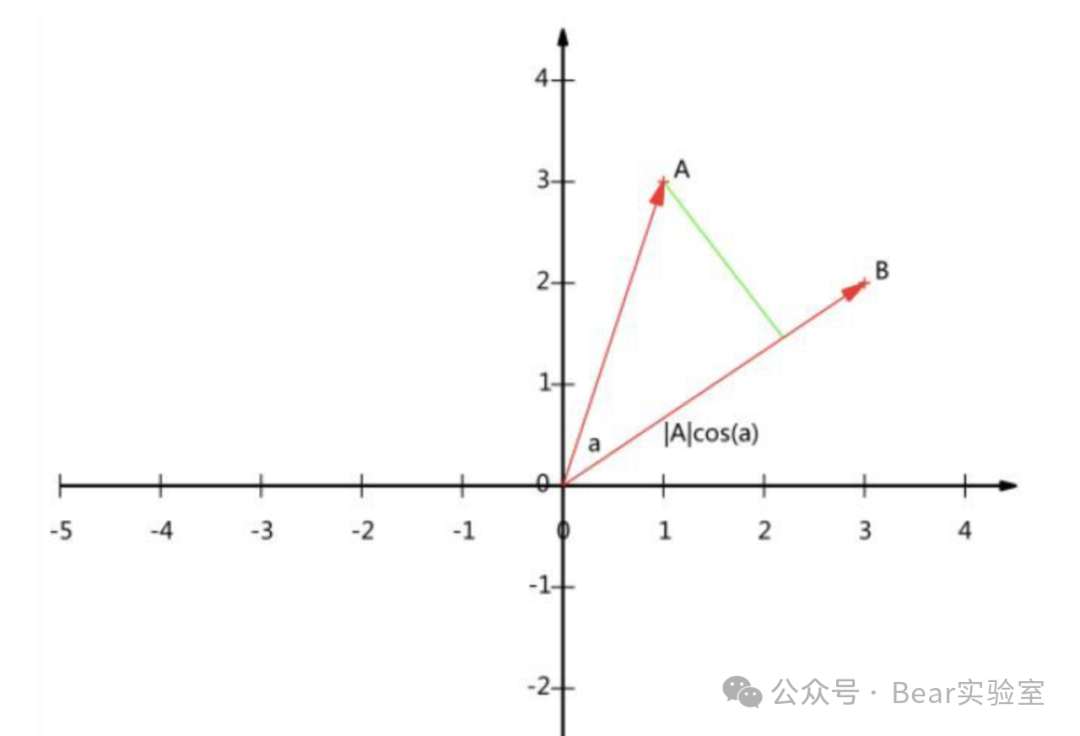
如果两个向量在各个维度的分量成比例,则它们的夹角为零。 -
如果一个向量在所有的维度都相等,比如像(10,10,10,10,10,10,10,10)这样的向量,它可能和任何一个向量都不太接近。这个性质我们后面还要用到。
-
表示:在 NLP 中,语言中的每个唯一单词都表示为连续向量空间中的密集向量。这些向量通常具有固定大小(如 100、300 或 512 维),与词汇量大小无关。 -
语境含义:与提供稀疏且无信息量的独热编码(其中每个单词只是长向量中的不同索引)不同,嵌入可以捕获有关单词的更多信息。具有相似含义或在相似语境中使用的单词在嵌入空间中往往更接近。例如,“国王”和“王后”可能由彼此接近的向量表示。 -
训练:可以使用 Word2Vec、GloVe 等算法或 BERT(用于上下文嵌入)等更高级的方法在大型文本语料库(如新闻文章、维基百科或网页)上对嵌入进行预训练。该模型会学习将具有相似含义的单词放在这个高维空间中。 -
降维:此表示允许降维。该模型不再处理数千或数百万个唯一单词,而是处理维度空间小得多的向量。 -
模型中的使用:这些向量表示随后可以被输入到各种机器学习模型(如神经网络)中,用于情感分析、机器翻译或内容推荐等任务。 -
超越词语:嵌入的概念超越了词语,包括句子、段落、用户 ID、产品等,其中相似的项目由嵌入空间中的接近的向量表示。
-
效率:它们提供了紧凑、密集的表示。 -
语义含义:它们捕捉单词或事物的深层语义含义。 -
灵活性:可以用于各种机器学习任务。 -
迁移学习:预先训练的嵌入可用于提高数据有限任务的性能。
-
cat = [1, 0, 0, 0, 0]dog = [0, 1, 0, 0, 0]fish = [0, 0, 1, 0, 0]run = [0, 0, 0, 1, 0]swim = [0, 0, 0, 0, 1]
-
训练:我们使用模型来学习嵌入。假设我们的模型学习二维嵌入(实际上,它们的维度要高得多,但为了简单起见,我们使用二维)。 -
得到的嵌入:模型可能会学习以如下方式表示这些单词:
-
cat=[0.9,0.1]dog = [0.85, 0.15]fish = [0.1, 0.8]run = [0.2, 0.7]swim = [0.15, 0.85]
-
相似性:请注意“cat”和“dog”在这个嵌入空间中彼此接近(两者在第一个维度上的值都较高,在第二个维度上的值较低)。这反映了它们作为宠物的相似性。 -
差异性:相比之下,“cat”和“swim”相距较远,表明相似性较低。 -
上下文分组: “rum”和“swim”等活动彼此之间距离更近,并且与“fish”(在上下文上与游泳相关)的距离比与“cat”或“dog”的距离更近。

