项目地址 https://github.com/stanfordnlp/dspy
-
将问题分解为多个步骤。 -
对每个步骤进行良好的提示,使其单独运行良好。 -
调整各个步骤以实现良好协作。 -
生成合成示例来微调每个步骤。 -
使用这些示例对较小的 LLM 进行微调以降低成本。
-
而且每次需要优化流程、LLM或者数据,可能就得重新设置Prompt或微调步骤。
-
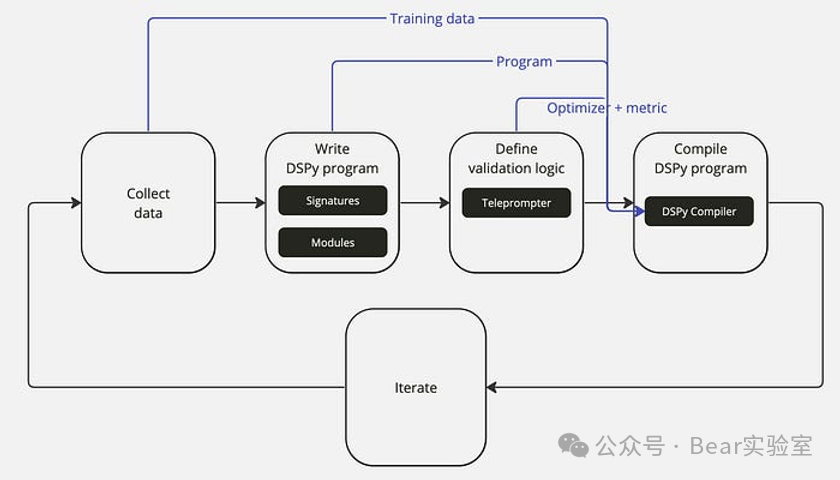
收集数据集:组合一系列输入输出示例(例如问答对)以完善您的管道。 -
开发 DSPy 程序:使用签名和模块制定程序逻辑,详细说明信息流以解决您的特定任务。 -
建立验证逻辑:根据验证指标和优化器(提词器)创建增强程序的标准。 -
使用 DSPy 进行编译:利用 DSPy 编译器,结合您的训练数据集、程序、优化器和验证指标来增强您的程序(例如,通过快速优化或微调)。 -
不断迭代完善:参与完善数据集、程序或验证逻辑的迭代循环,以达到管道所需的性能水平。
-
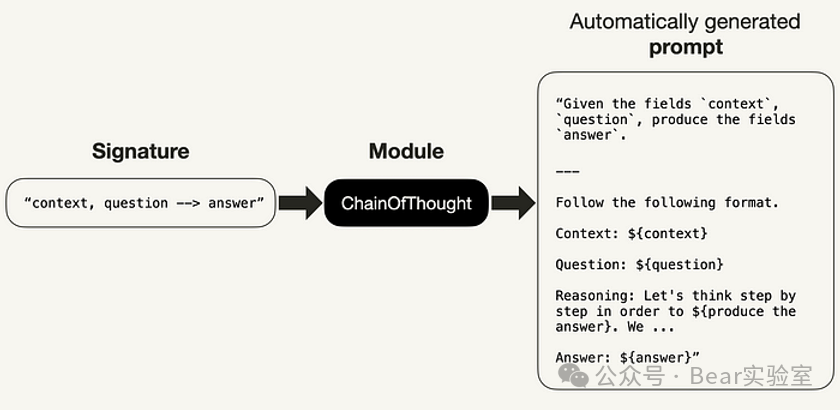
Signatures(签名):概述预期的行为,告诉LLM输入和输出是什么。 -
Modules(模块):构建利用大型语言模型 (LLM) 的程序的基础组件。 -
Optimizer(优化器):旨在调整 DSPy 程序的设置,包括Prompt和语言模型 (LM) 权重
-
与主要描述参数的传统函数签名不同,DSPy 签名可以主动塑造和控制模块的行为。 -
DSPy Signatures 中使用的术语至关重要;它清楚地传达了语义角色,区分了“question”和“answer”或“sql_query”和“python_code”等元素。
-
问答: "question -> answer" -
情绪分类: "sentence -> sentiment" -
摘要: "document -> summary"
-
检索增强问答: "context, question -> answer" -

-
带推理的多项选择题回答:"question, choices -> reasoning, selection"
对于字段,任何有效的变量名都可以!字段名应该具有语义意义,但要从简单开始,不要过早优化关键字!将这种黑客行为留给 DSPy 编译器。例如,"document -> summary"、"text -> gist"、"long_context -> tldr"。


-
每个内置模块都抽象出一种提示技术(如思路链或 ReAct)。至关重要的是,它们被泛化以处理任何DSPy 签名。 -
DSPy 模块具有可学习的参数(即,组成提示和 LM 权重的小片段),可以被调用(调用)来处理输入和返回输出。 -
多个模块可以组合成更大的模块(程序)。DSPy 模块直接受到 PyTorch 中的 NN 模块的启发,但应用于 LLM 程序。
-
dspy.Predict:基本预测器。不修改签名。处理学习的关键形式(即存储指令和演示并更新到 LM)。 -
dspy.ChainOfThought:教导 LLM 在做出签名回应之前逐步思考。 -
dspy.ProgramOfThought:教导 LLM 输出代码,其执行结果将决定响应。 -
dspy.ReAct:可以使用工具来实现给定签名的代理。 -
dspy.MultiChainComparison:可以比较多个输出以ChainOfThought产生最终预测。
我们还有一些函数式模块: -
dspy.majority:可以进行基本投票,从一组预测中返回最受欢迎的回应。
compile来跟踪您的 LLM 调用。这意味着,你可以自由调用模块,无需为链式调用做任何奇怪的抽象。这基本上是 PyTorch 针对运行定义/动态计算图的设计方法。-
DSPy 程序:这可以是简单的单一模块(如dspy.Predict ),也可以是涉及多个模块协同工作的更复杂的设置。 -
指标:通过分配分数来评估程序输出的函数,分数越高表示性能越好。 -
一组训练输入:即使数量不多(约 5 到 10 个示例),可能不完整(仅包含程序的输入而没有相应的输出),也可能足够了。