

点击蓝字
关注我们
01
前言
抱歉啊,好久没更新了。不过,也确实没闲着。
最近初步尝试了Langchain,发现《langchain入门指南》这本书中的例子用的都是openaiembeddings,这个需要魔法。为此,经过查阅官方文档和CSDN,找到了合适的方法,同时说说其中的坑。
02
干货
对于中文,目前个人用得比较多的就是m3e和bge-large-zh。
m3e
m3e属于HF系列,根据网上信息(需亲自验证),该系列的embedding模型都可以尝试使用下列方式进行向量模型加载:
from langchain.embeddings importHuggingFaceEmbeddings
bge
bge的效果目前是首屈一指的,该模型在langchain框架中的导入方法是:
from langchain.embeddings importHuggingFaceBgeEmbeddings
03
避坑
(1)网上也有用ModelScopeEmbeddings的:
embeddings=ModelScopeEmbeddings(model_id='iic/nlp_corom_sentence-embedding_chinese-base')
我试了一下,除了示例中的这个模型可以正常使用,m3e、bge以及很多其它模型都会报错:
please check whether model config exists in configuration.json

(2)bge模型与chatglm3大模型不匹配,导致在与大模型对话时报错:
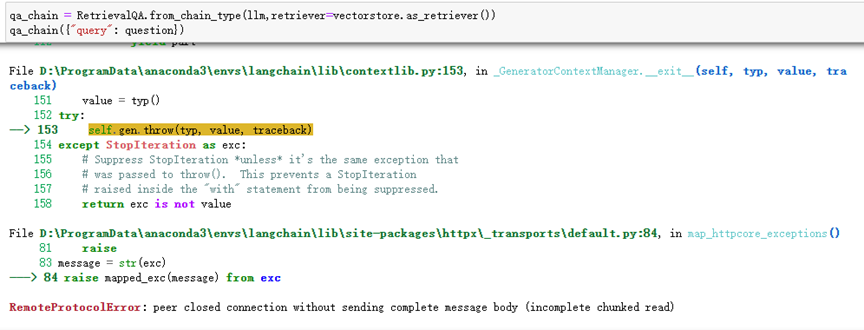
同时,后台输出方面,bge与m3e的差别在于参数”tool”和”functions”的不同。


目前尝试后的结论是:
m3e的适用性较强,可以与chatglm和Qwen大模型进行匹配交互,bge目前仅限于Qwen大模型,其它的,我也不知道。
