


一、前言
ChatGPT 整体的训练过程复杂,虽然基于DeepSpeed 可以通过单机多卡、多机多卡、流水线并行等操作来训练和微调大语言模型,但是没有端到端的基于人类反馈机制的强化学习的规模化系统,仍然会造成训练类ChatGPT 系统非常困难。
二、DeepSpeed-Chat SFT 实践
DeepSpeed-Chat是微软于2023 年4月发布的基于DeepSpeed 用于训练类ChatGPT 模型的开发工具。 基于DeepSpeed-Chat 训练类ChatGPT 对话模型的步骤框架如图所示,包含以下三个步骤。 (1)有监督微调(SFT) (2)奖励模型微调 (3)RLHF 训练
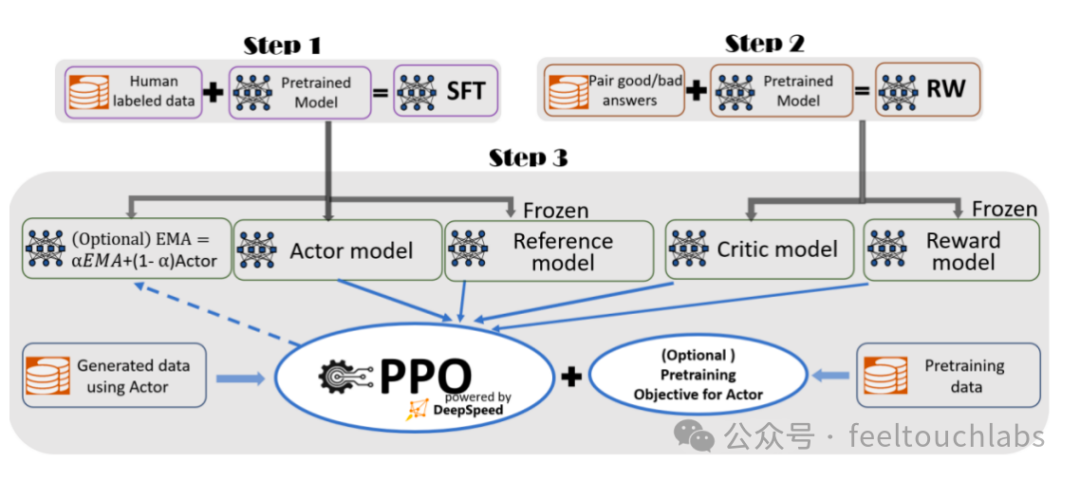
DeepSpeed-Chat 具有以下三大核心功能。
-
(1)易用的类ChatGPT 模型的训练和强化推理:只需要一个脚本就可以实现多个训练步骤 -
(2)DeepSpeed-RLHF 管道:DeepSpeed-RLHF 复现了InstructGPT论文中的训练模式; -
(3)DeepSpeed-RLHF 系统:将DeepSpeed 的训练能力(Training Engine)和推理能力。
三、Chat代码分析
DeepSpeed-Chat 代码仓库位于微软官方GitHub 仓库DeepSpeedExamples/applications/DeepSpeed-Chat 路径下。在进行实际应用前,需要先对官方代码有一个全局的了解。DeepSpeed-Chat 代码的结构如下所示:
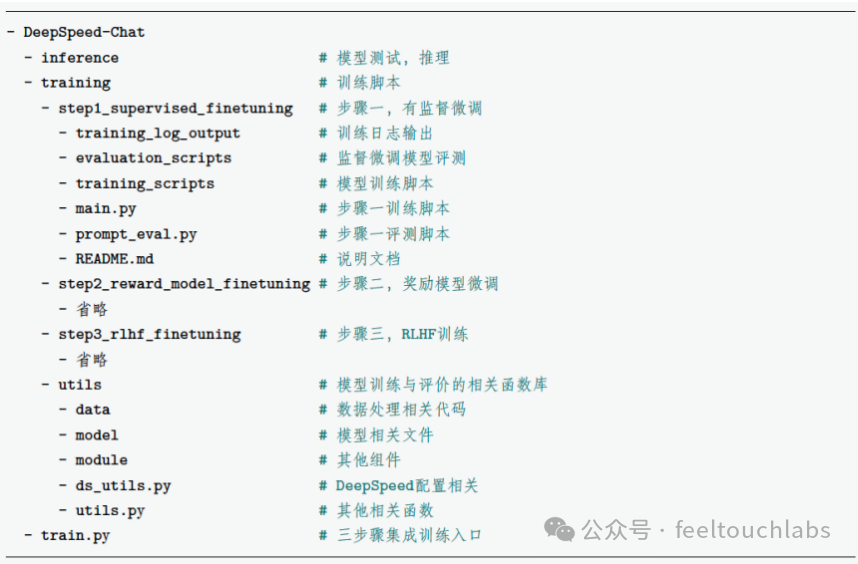
当需要完整微调一个模型时(包含所有步骤),可以直接运行train.py 程序。训练中主要调整如下参数。 –step 训练步骤参数,表示运行哪个步骤,可选参数为1、2、3。本节介绍的内容只使用步骤一,有监督微调。 –deployment-type 表示分布式训练模型的参数,分别为单卡single_gpu、单机多卡single_node 和多机多卡multi_node。 –actor-model 表示要训练的模型,默认参数为训练OPT 的"1.3b"、"6.7b"、"13b"、"66b" 等各个参数量的模型。 –reward-model 表示要训练的奖励模型,默认参数为OPT 的"350m" 参数量的模型。 –actor-zero-stage 表示有监督微调的DeepSpeed 分布式训练配置。 –reward-zero-stage 表示训练奖励的DeepSpeed 分布式训练配置。 –output-dir 表示训练过程和结果的输出路径。
