MinerU是一款将PDF转化为机器可读格式的工具(如markdown、json),可以方便的抽取为任意格式。
-
-
输出符合人类阅读顺序的文本,适用于单栏、多栏以及复杂排版
-
-
-
-
-
自动检测扫描版PDF和乱码PDF,并启用OCR功能
-
支持纯CPU环境运行,并支持GPU(CUDA)/NPU(CANN)/MPS加速
-
pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simplepip install uv -i https://mirrors.aliyun.com/pypi/simpleuv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple
git clone https://github.com/opendatalab/MinerU.gitcd MinerUuv pip install -e .[core] -i https://mirrors.aliyun.com/pypi/simple
mineru -p <input_path> -o <output_path>
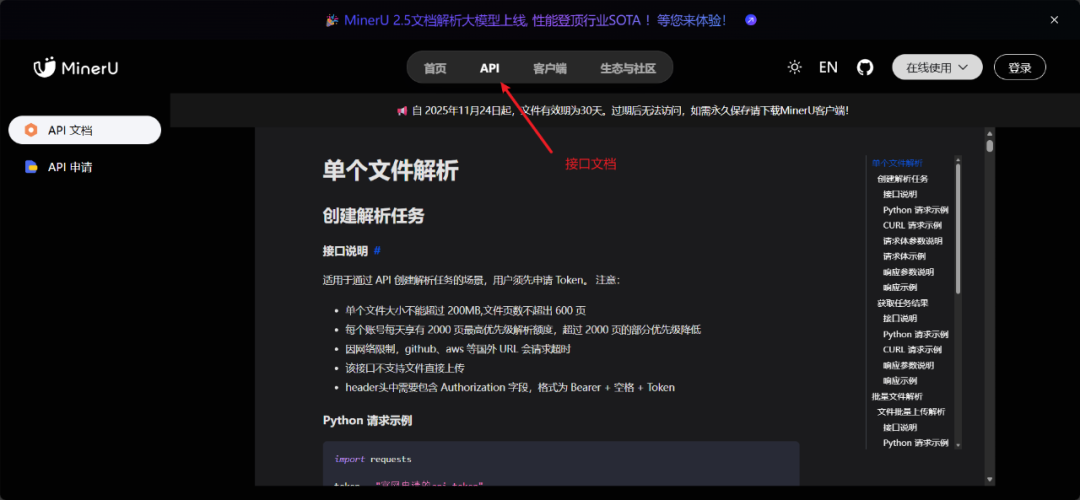
eg:可以通过命令行、API、WebUI等多种方式使用MinerU进行PDF解析
import requests
token = "官网申请的api token"url = "https://mineru.net/api/v4/extract/task"header = { "Content-Type": "application/json", "Authorization": f"Bearer {token}"}data = { "url": "https://cdn-mineru.openxlab.org.cn/demo/example.pdf", "model_version": "vlm"}
res = requests.post(url,headers=header,json=data)print(res.status_code)print(res.json())print(res.json()["data"])
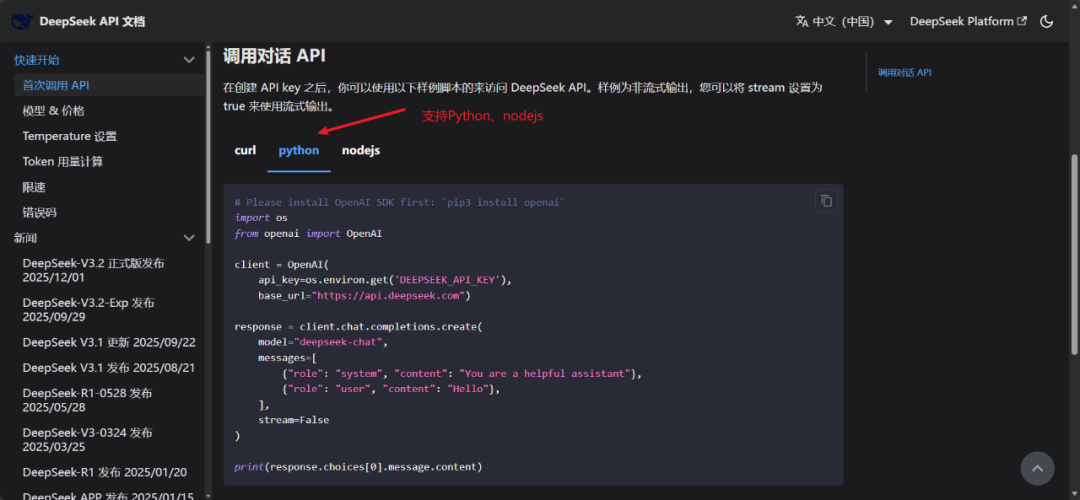
语言为Python!再看看DeepSeek接口文档
在AI领域,Python是首选,看到这里,想起了没,读过我写的dify使用的教程的小伙伴知道,Dify中的脚本节点支持的是Python和nodejs!
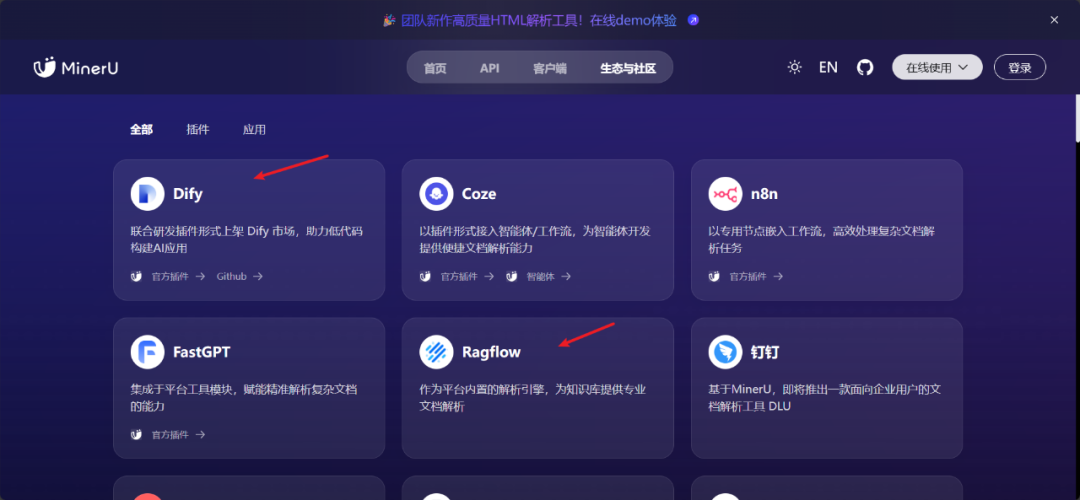
MinerU的生态也挺不错的,支持Dify和Ragflow,适合小企业本地部署,完成AI应用的需求开发。