导读 本文将分享面向 Data+AI 的数据湖技术。
1. AI 时代下数据湖面临的挑战
2. Apache Iceberg 简介
3. 基于 PyIceberg 的 AI 训练/推理链路
4. Iceberg 向量表与向量查询
分享嘉宾|李志方博士 腾讯 高级工程师
编辑整理|王跃辉
内容校对|李瑶
出品社区|DataFun
AI 时代下数据湖面临的挑战

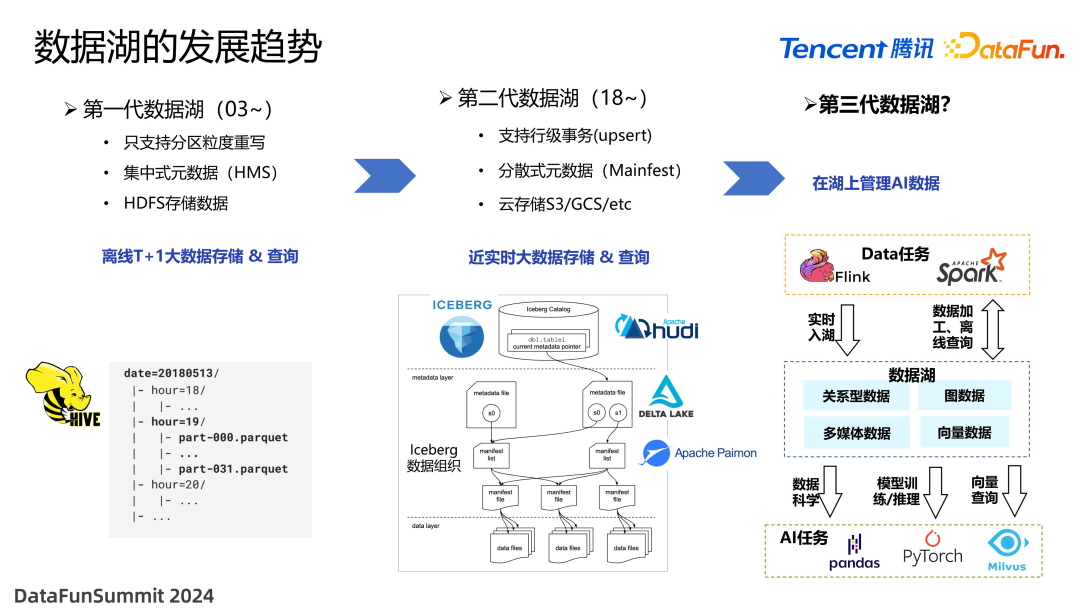
第一代数据湖起源于 Google 的 3 篇重要论文,是以 Hadoop、Hive 为核心的一套技术,主要的应用场景是离线 T+1 的大数据存储和查询。这代数据湖的查询性能是比较不错的,但是受制于当时的设计思想,只能支持分区级别的重写,采用集中式元数据,因此当分区数量很大的时候,就会遇到元数据的瓶颈,并且查询时 planning 的时间也会比较久。存储大部分局限于 HDFS,并没有很好地兼容各种云存储。
2018 年前后开启了第二代数据湖,以 Iceberg、Hudi、Delta Lake、Paimon 为代表。这一时期非常强调实时或近实时更新能力,一般可以支持行级事务更新,比如 offset 能力,元数据采用 manifest 机制、分散式存储,具有比较低的 planning 开销。并且在这代数据湖上,增加了很多云存储的支持。
当前,随着大模型 AI 技术的火热,新一代数据将与 AI 紧密相连,这里我们称之为第三代数据湖。在数据湖上存储的,除了已经有的关系型数据以外,还会增加一些与 AI 有关的,比如多媒体数据、向量数据、图数据等。在数据湖上既可以做 data 相关的负载,比如实时入湖,以及基于 Spark 的查询,ETL 作业,还可以在数据湖的基础上实现数据科学、模型推理训练,甚至向量查询的功能。这样,在一套数据平台上,既可以支持 AI,也可以支持 data 负载,可以极大地减少算法开发人员的负担,让整个流程更加丝滑。
基于对腾讯内部一些 AI 场景的分析和对一些前沿工作的调研,我们总结出了当前 AI场景下面临的一些痛点。(下图来自于第三代数据湖的一家代表性创业公司。)
首先,AI 是一个非常复杂的、系统性的工程,其整个数据链路包括多个不同的阶段,比如数据采集、归档特征工程、训练部署以及监控等等。在不同阶段可能采用不同的存储格式、不同系统,在整条链路中需要通过 ETL 程序去串联,时效性较差。如果想要对数据进行修改,比如 update、delete、增加列、减列等等,由于数据分散在不同的层次当中,对这些操作是难以支持的,工作量非常大。同时数据版本也难以管理,对一条数据进行修改可能涉及到上下游多个阶段的修改。因此在传统体系下,AI 数据的管理是比较困难的。
另外,读写性能也较差。不同存储,格式不同,我们需要进行大量的序列化、反序列化,还要在不同的存储介质间进行重复 I/O,显然效率较低。
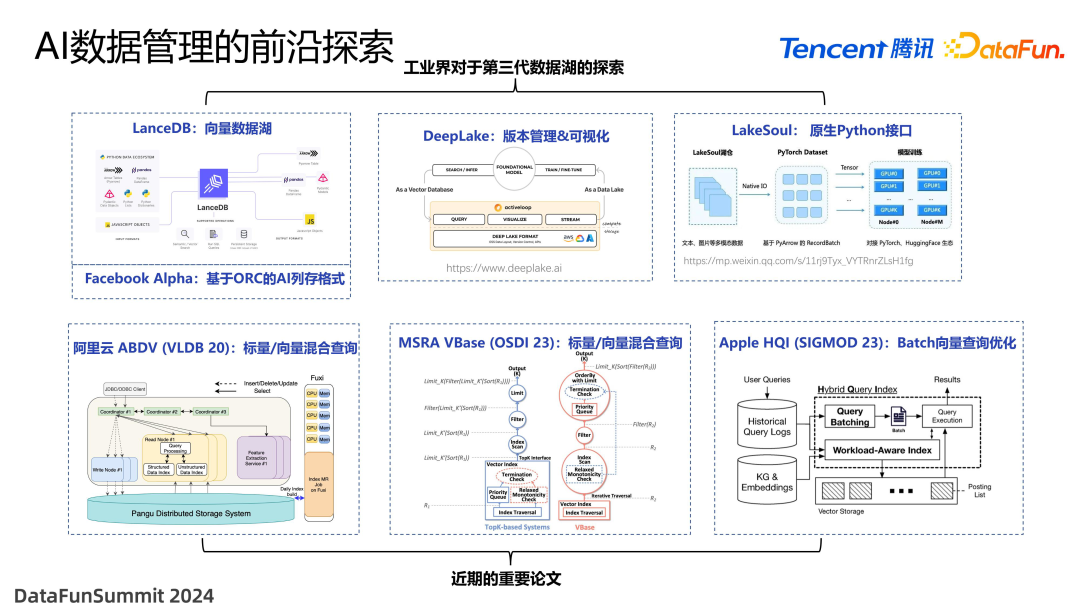
为了解决前面提到的问题,目前一些数据湖的创业公司,已经开始将重点转向了 AI 方向。比如 LanceDB 率先提出了向量数据湖的概念,它与向量数据库是有区别的,整体存储形态类似于湖,其上可以存储一些向量数据,也可以存储一些多媒体的数据。DeepLake 与 LanceDB 类似,但是它有非常好用的可视化界面,可以在一个平台上对图片进行一些编辑操作,对数据集进行可视化的清洗,还支持类似于数据湖 git branch 的版本管理操作,极大地方便了多团队间的协作。LakeSoul 也是一家创业公司,他们的数据湖提供了原生的 Python 接口,可以很方便地将数据湖的数据跟模型训练进行挂钩。
学术界对 AI 数据管理方面也非常重视。近几年向量数据库的逐渐崛起,引起了阿里云、微软亚研院和苹果等一些大公司对相关技术的探索。例如苹果在知识图谱的应用当中提出了 Batch 向量查询优化,与数据湖场景类似,也是基于高吞吐批量执行的背景。
Apache Iceberg 简介
接下来介绍我们以 Iceberg 为基础,面向 AI 进行的一些工作。
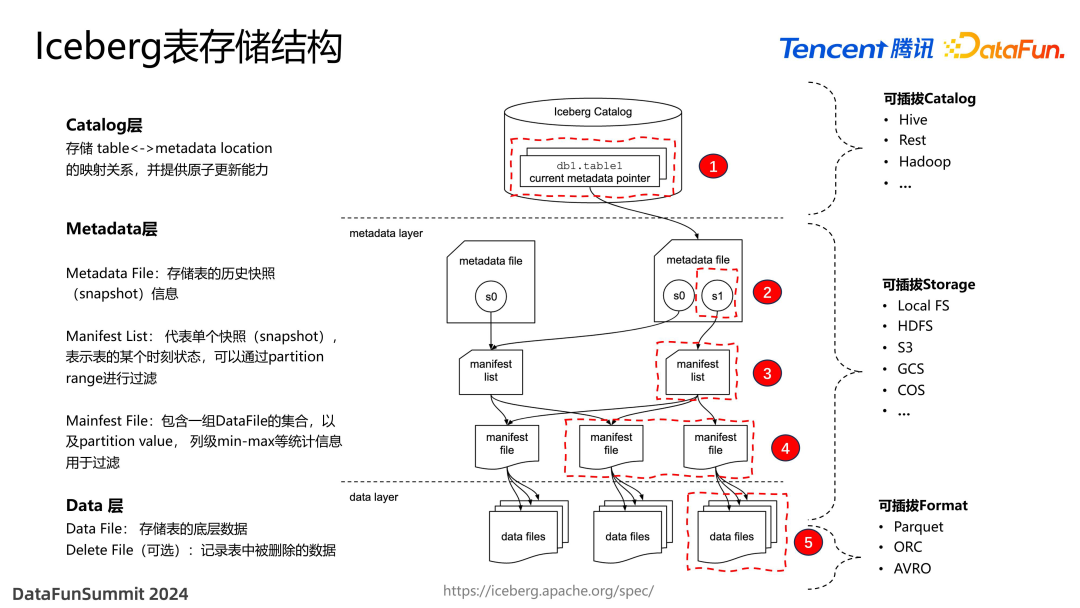
首先是 Catalog 层,是比较轻量级的一个服务,一般是用来存储 table 与其 metadata 的 location 之间的映射关系,可以提供原子更新能力,用来保证事务性。
第二层元数据层,由一系列的文件组成,首先是 metadata file,存储整个 table 级别历史快照指针的集合,通过它可以在下游找到 manifest list,即 data file 的指针,在每一级上记录一些统计信息,比如 partition 值,或者是列级的 Min Max,经过 manifest list 和 manifest file 这两层过滤之后,可以得到一个相对比较小的 data file 的集合。这时候就可以交给查询引擎去执行了。
Iceberg 设计时有一个特别重要的特点,就是它非常强调格式的可拓展性,其每层结构都是可拓展的。比如 catalog 有多种实现,包括 Hive、Rest、Hadoop 等;Storage 也是支持多层的;底层的 data files 也可以支持多种存储格式,所以数据格式是非常灵活的。
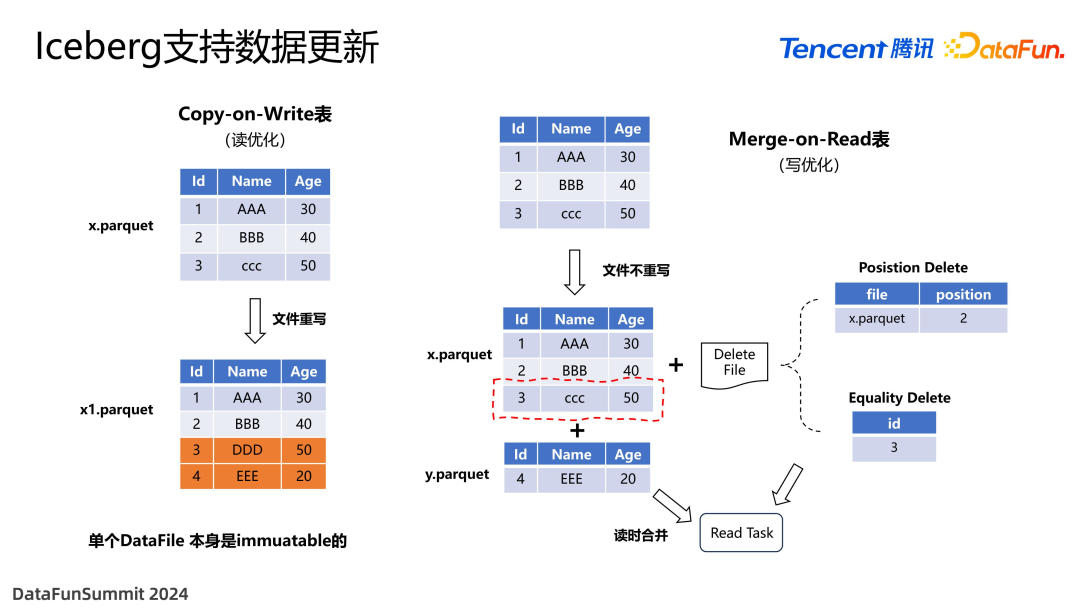
上图展示了 Iceberg 支持数据更新的过程。Data files 默认采取 parquet 列存,这种格式的特点是数据格式都是 immutable 的,无法对数据文件内容进行修改。所以 Iceberg 的数据更新方式并不是直接在本地修改,而是采用两种方式。
一种方式是 copy on write。这是一种读优化操作,在写入时,将更新值重新生成一个新的文件,再通过 manifest 元数据的指针体系挂载到 catalog。这种方法的好处是读优化性能比较强,因为数据是被重写过的,在读取过程中没有任何额外的开销。
另外一种是 merge on read,其特点是写优化。前一种方式需要进行数据的重写,如果数据量少,其实不是特别划算。所以引入了 data file 的机制,记录哪些行或者哪些值是被删除的,读数据时进行合并,因为读取时要进行一些额外的工作,所以读性能相对较差。
正是由于每一个 data file 都是 immutable 的,无法原地更新,这也影响了索引的设计。
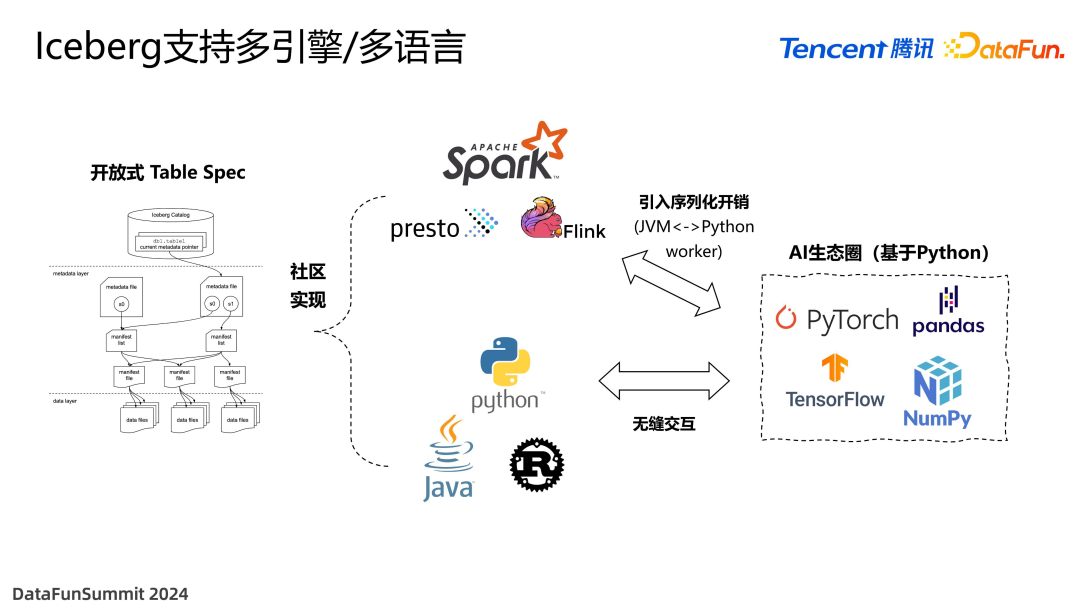
Iceberg 具有非常强的开放性,Table Spec 采用标准规范化的格式,定义了每一层的每种文件存储内容的格式,以及读写方式。社区基于此实现了多套不同的引擎包,比如 Spark、Flink 等等。同时还支持多语言的 API,比如 Python、Java、Rust 等。
值得注意的是,目前 AI 生态圈大部分都是基于 Python 的生产环境,但传统的比如 Spark 引擎,虽然也有 PySpark 模式,但并不是特别友好,因为它本质上是 JVM 加上 Python worker 的架构,会引入大量序列化开销,同时调试也是非常困难的。而 Iceberg 提供了 Python 接口,为结合 AI 工作流提供了很大的帮助。
基于 PyIceberg 的 AI 训练/推理链路
接下来将介绍利用 Iceberg 社区提供的 PyIceberg 进行 AI 模型训练和推理的实践。
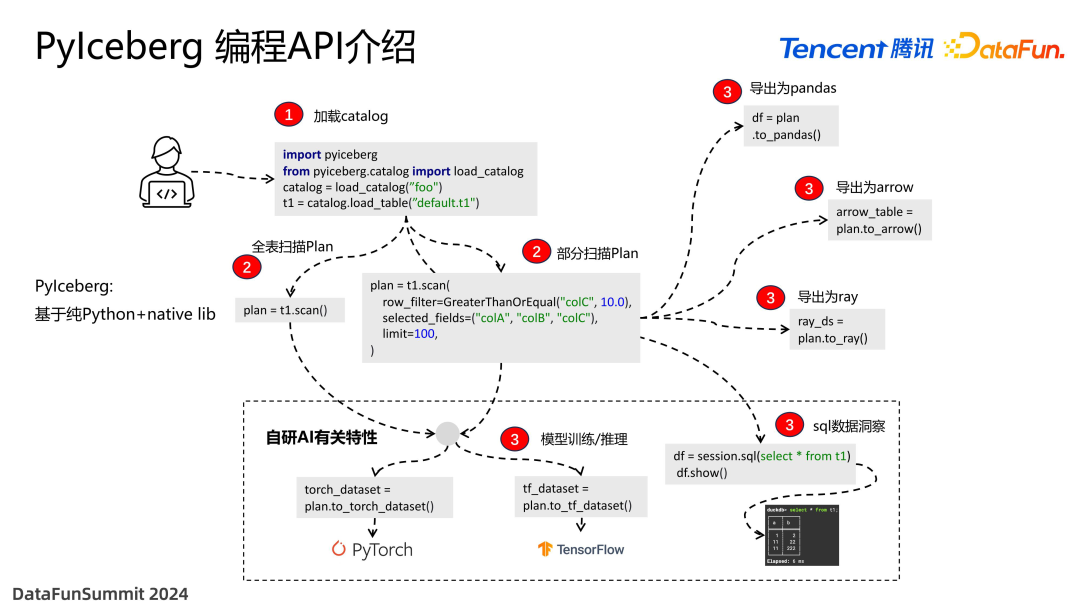
PyIceberg API 使用非常简便,只需要几行代码就可以进行业务开发。
首先是加载 catalog,对接 Hive、Hadoop 等,提前配置好就可以拿到元数据。比如图中所示,加载 t1 这个 table,读取元数据的 location,再根据业务场景做 planning,默认情况下可以进行全表的 planning,当然也可以做部分扫描,比如指定某个条件大于 10。还可以选择过滤哪些列,因为 AI 常用到非常大的宽表,而我们可能只需要其中几列,这样可以减少加载时间。在一些小的实验,不需要太多数据时还可以指定 limit 行数。
Planning 完成后开始进行真正的执行,将数据转换为 AI 实验所需要的格式,比如 pandas、arrow、ray 等,来做后续分布式的执行。
我们内部还研发了一些 API,应用在 AI 相关场景中。比如把 Iceberg 转成 PyTorch 或 TensorFlow dataset,就可以直接与训练框架进行无缝对接。还可以在 SQL 上下文中输入简单的 SQL 语句,查看返回的结果,便于算法调试。避免了用户在不同上下文反复切换,提升了使用体验。
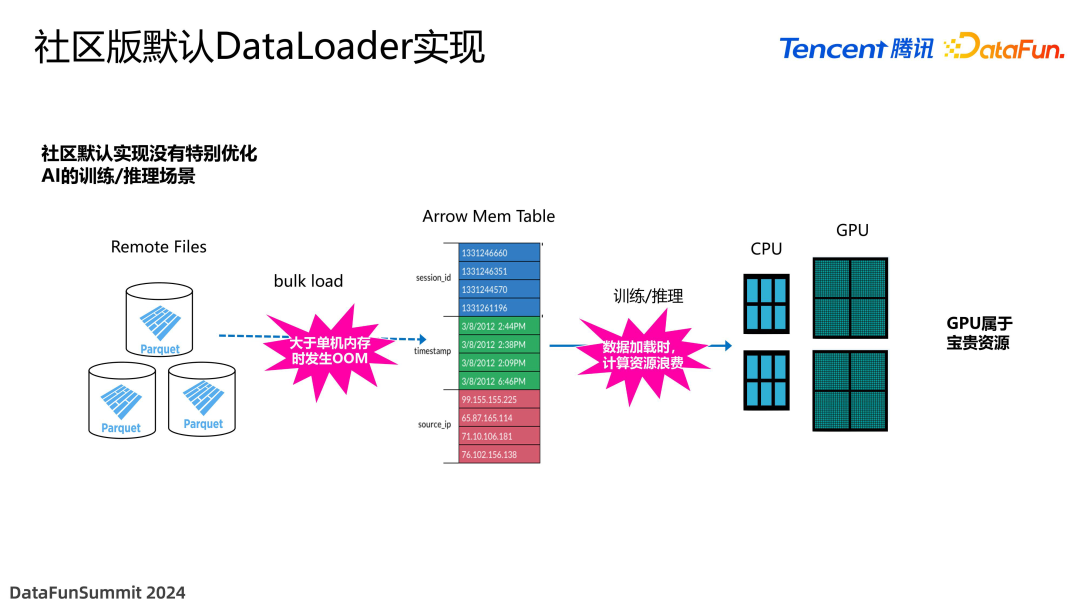
接下来介绍关于 AI 训练的 Data Loader 的实现。社区版没有提供专门的 Data Loader 能力,只是相对比较基础的 bulk load 的形式,在 planning 结束之后,需要将所有的 data files 一次性全部载入内存,形成一个大的 Arrow Mem Table 来进行后续操作。这个操作在生产中,涉及数据量较大的表时,很容易发生 OOM,并且在此期间 GPU 资源也存在浪费。
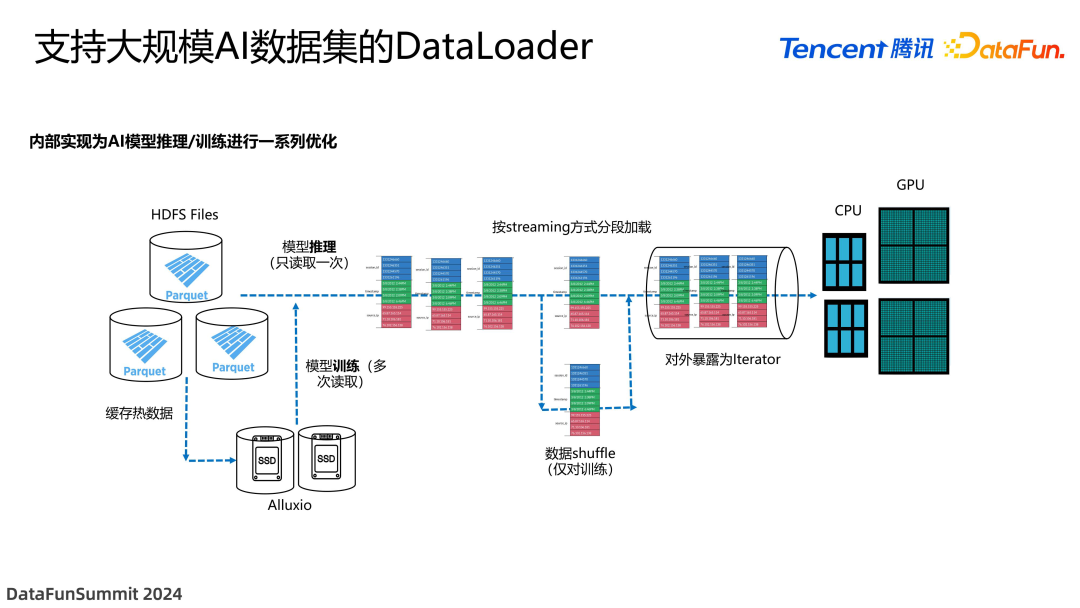
针对上述问题,我们开发一个支持 AI 大数据集的 DataLoader,其主要思想是不采用一次性加载,而是以 streaming 的方式进行分段加载,加载成多个小的 arrow 片段,对外暴露为 iterator 形式,后续逐渐加载。这样实现的好处是 GPU 可以边计算边加载,并且只需要一小部分内存就可以了。
针对训练和推理这两种不同的场景,做法有所不同。推理时数据只会通过一遍,但训练中数据可能会反复迭代多次,这样存在着一定的数据局部性,这份数据相当于是个热数据,这时可以利用 Alluxio 进行缓存,因为它里面有 SSD,可以缓存训练当中重复使用的数据。并且训练时还有个特殊的要求,这些 iterator 需要打乱数据的排序,所以返回训练框架之前还会做一个 shuffle 的操作。
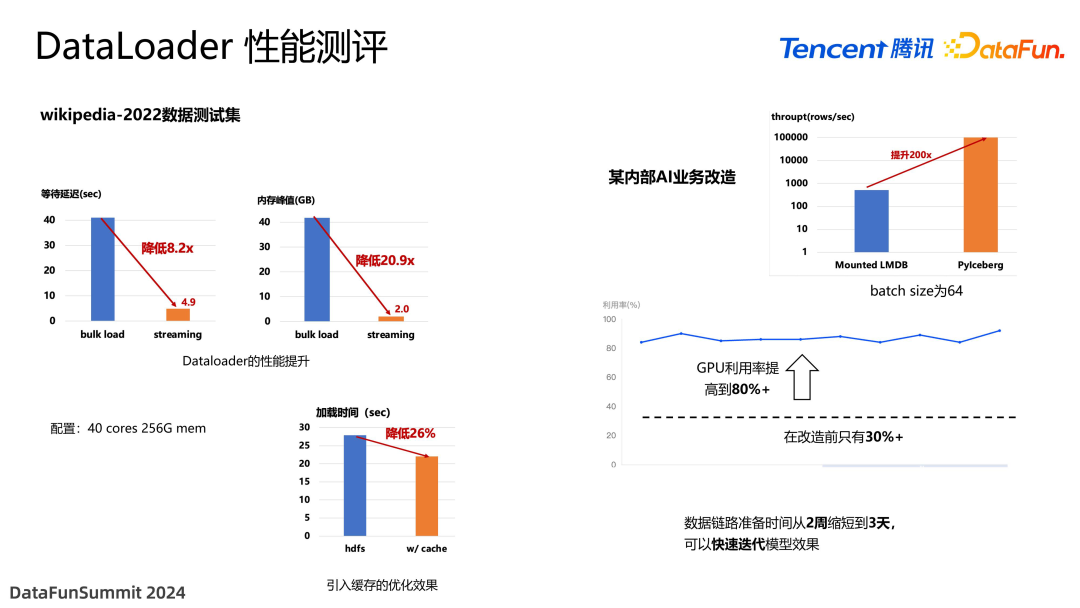
我们以 wikipedia-2022 数据集对 DataLoader 进行了性能测评。可以看到,相比于默认的 bulk load 的形式,等待时间大幅降低,从几十秒降低到了几秒,并且内存峰值也大幅度下降。这样就减少了对 GPU 资源的浪费。
另外,还测试了引入 Alluxio 缓存的效果,降低了 26% 的 IO 加载时间。因为已经达到了网卡的上限,没有办法提供更大的加速,但如果换更好的环境,加速效果应该会更好。
此后,在内部某业务部门进行了联调上线。该部门原来通过挂载 LMDB 的形式,非常低效。加入了 PyIceberg 的改造后,数据加载速度提高了 200 倍,并且 GPU 的利用效率从原来的平均 30%+ 提高到了 80% 以上。最重要的一点是改善了开发体验,用户准备时间从周级别缩短到了短短几天,用户可以进行比较快速的模型迭代,不需要面对多种存储格式,只要在湖上使用 SQL 语言来操作即可,不需要引入第三方存储介质。
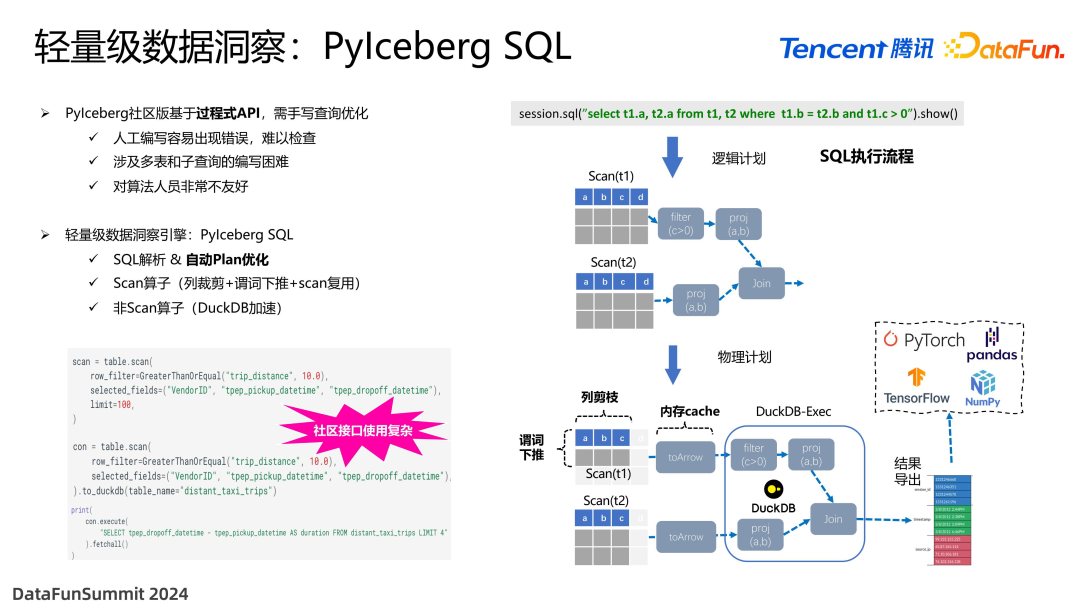
接下来介绍另外一个 PyIceberg 使用的问题。社区 API 是基于声明式的 API,需要手工编写哪些列是需要进行过滤的,哪些谓词是需要进行下推的。因此对用户的要求非常高,用户需要仔细评估业务逻辑,然后转换成代码。对单表的场景,也许勉强可以接受,但如果是多张表查询的复杂情况,显然人力很难实现,而且可能会导致一些不必要的错误,这些错误是非常难被发现的。
针对这个问题,我们开发了一个叫做 PyIceberg SQL 的子系统。用户可以通过直接输入 SQL 的形式来进行后续的查询,系统会自动进行执行计划的解析,包括列裁剪和谓词下推。具体针对一个 SQL,我们将执行计划分成 scan 部分和非 scan 部分。Scan 部分利用 PyIceberg 现有 API 就可以实现,最终的产物是到内存的 arrow 当中。非 scan 部分,将转发给 DuckDB 来进行执行,DuckDB 是一个轻量级内存查询引擎,它可以对内存的数据进行非常快的查询。查询出来的结果,除了可以让用户在返回结果当中看到,也可以选择导出成 arrow 格式,以继续对接后续训练框架或数据科学框架。
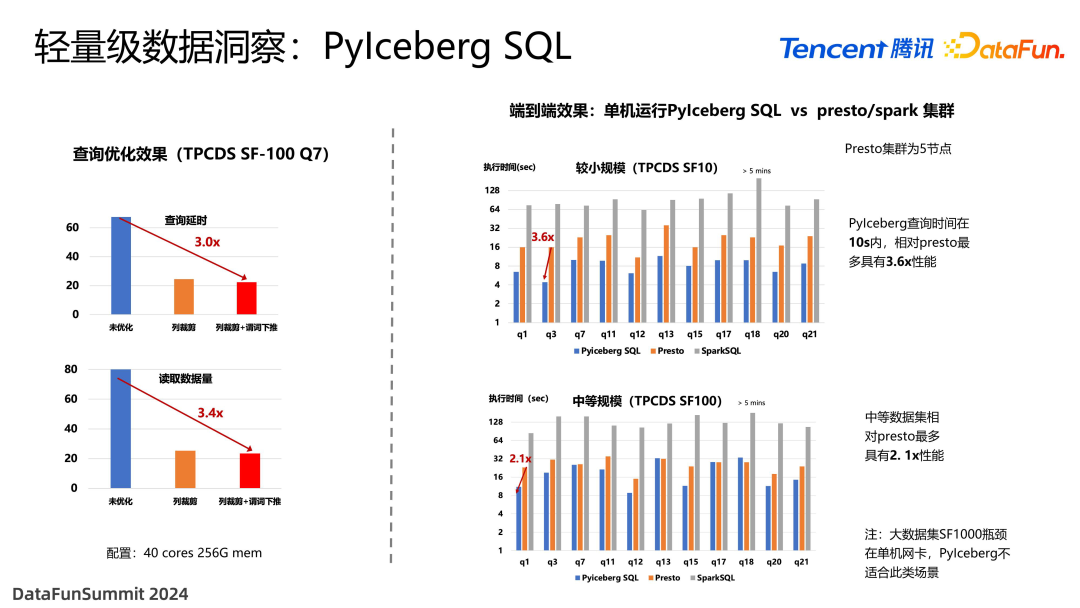
上图展示了 PyIceberg SQL 的查询效果,对于 SF-100 数据集,可以看出获得了明显的查询延时提升,以及数据量的提升。需要注意是,这是一个单机的引擎,是在 python 进程当中去使用的,并不是分布式执行引擎。我们将这个单机引擎和分布式的 Presto 甚至 Spark 来进行比较,对于小数据集,比如 SF-10 这种特别小的数据集,可以在几秒钟之内返回,相对于 Presto 具有很大的优势。因为它只是单机运行,没有进行分布式的 shuffle,并且 DuckDB 是高度优化的系统,它的纯计算可能在几十毫秒之内就完成了,这对于算法调试已经足够了。针对于中等规模,比如 SF-100 数据集,我们仍然有部分优势。但当数据集特别大,比如 SF-1000 这个级别的时候,PyIceberg SQL 的性能相对于传统数据系统就没有优势了。因为这时候单机网卡已经达到上限,但是分布式可以用多张网卡的下行带宽来去做并行加载,这时的带宽变成了 IO 瓶颈。这套实现的优势不在这里,主要还是为了算法的快速调试,而不是做大型系统查询。
Iceberg 向量表与向量查询
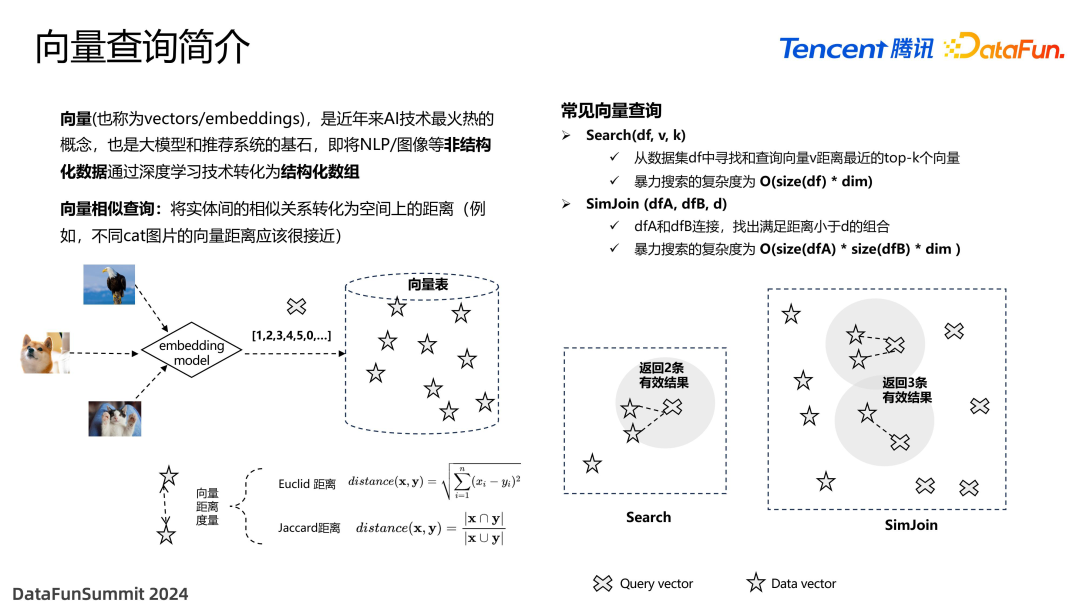
向量是目前非常火热的一个概念。随着大模型的崛起,向量变得至关重要,通过 AI 模型将 NLP 以及图像这些非结构化数据转变成结构化的数组,并存储在向量表当中,就可以通过一些数据库的方法来进行处理。比如一张猫的图片,变成 embedding 数组后,我们去向量表中查询,如果找到一张表和它距离比较接近,就可以返回很多个类似于猫的图像。如上图,衡量任意两个五角星的距离,也就是衡量向量之间的距离有不同的算法,比如最基础的 Euclid 距离,就跟平面的或者立体的距离的定义是一样的,是对每个维度做差,再求平方根。还有 Jaccard 距离,是衡量集合相似度,也就是交集的基数除以并集的基数。
向量查询有很多种,这里介绍其中两种最经典的方式。第一种是 Search,参数包括 data file/table、查询向量和k 值。其含义是在一个大段的数据集当中寻找与查询向量最接近的 k 个向量,将其返回。另外一种是向量的连接运算,输入是两个 table,找出其中距离小于 d 的组合。如图所示,这两种不同集合之间,一共找到了三组满足距离约束的组合,将其返回。
向量计算在暴力搜索的情况下,其复杂度是非常高的。以 Search 为例,它的计算复杂度等于这个表大小再乘以每个向量的维度。比如 Euclid 公式,与向量的维度是成正比的,每一个点都需要进行搜索,再进行排序。对于向量的连接就更大了,相当于是笛卡尔积的运算。可见在暴力检索的情况下,很难快速返回出结果。
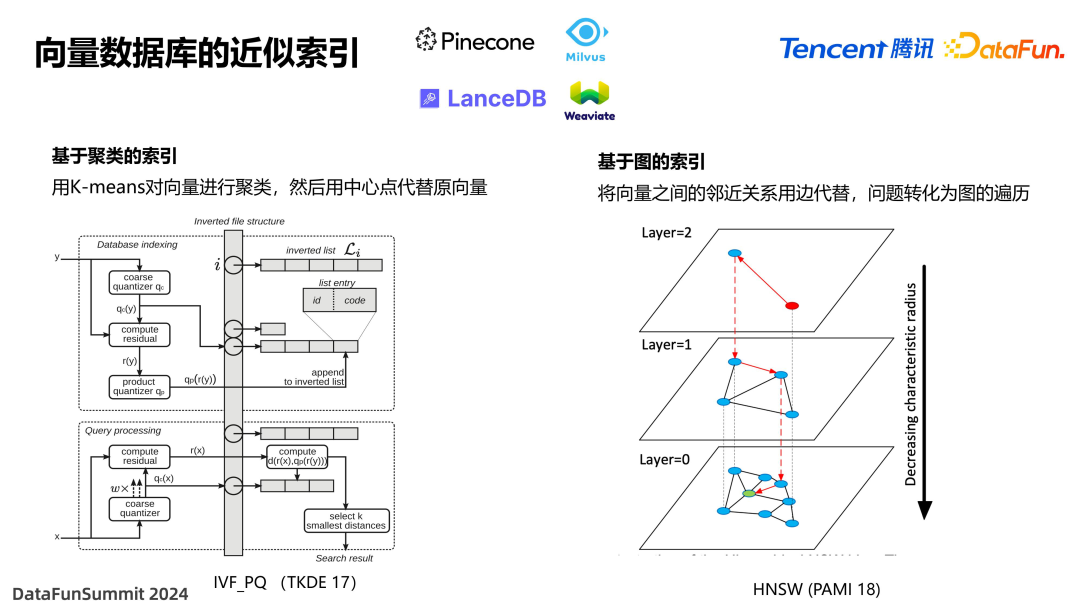
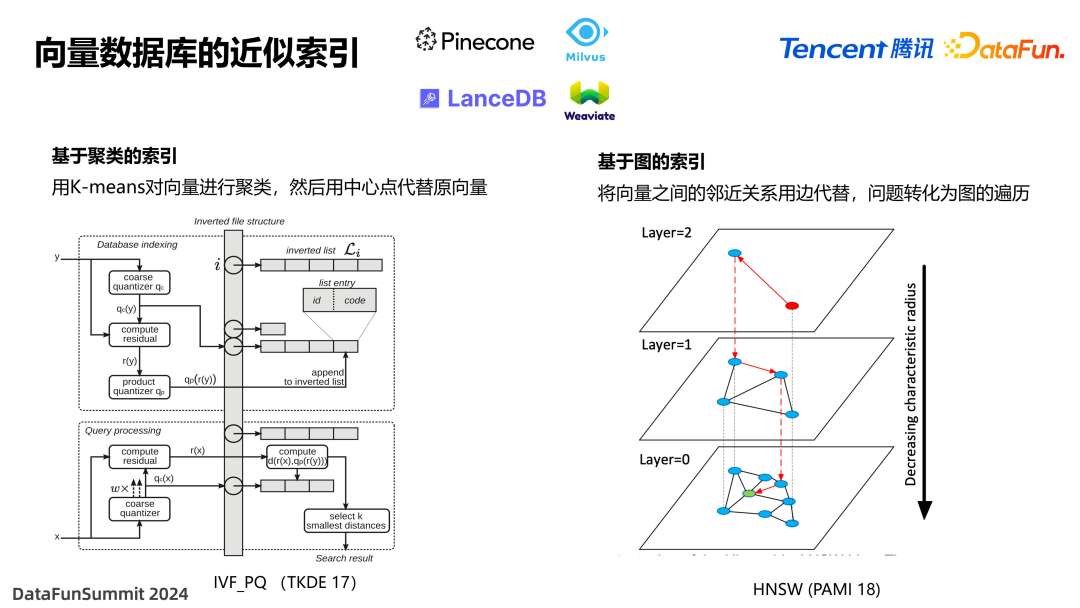
为了解决这个问题,目前非常火热的一些向量数据库采用了向量近似索引技术,来实现快速执行。比如目前最经典的两种,一种是基于聚类的索引,是将一组向量通过 K-means 算法来进行聚类,聚成多少个中心点之后,再以中心点来代替这一簇向量。相当于将多个数据集进行了粗略的归类,这样只需要在那一个簇的附近去搜索就可以了。当然,实际实现时可能会更复杂,需要采用两层的 K-means 的聚类,工业界最常见的是 IVF-PQ 算法。
另一种是基于图的索引,把向量之间的邻近关系用一个边来代替,找最近节点的问题就转化为图的遍历,在图当中去搜寻最近的几个顶点。具体实现时,将图分为多层,每一层是上一层的摘要,搜索时是自顶向下地进行搜索。通过图的索引找到最接近的几个顶点。
引入了这样的索引之后,会自然地认为数据湖可以比较容易地支持向量查询,但实际上并没有那么直接。
首先上述两种索引实现上的要求跟数据湖的很多设计思想是相违背的。比如数据湖 Iceberg、Paimon 等都比较强调实时入湖的场景,而 IVF-PQ 索引是基于聚类的,数据插入后需要重新训练,显然无法支持实时场景。因为 K-means 算法计算量非常大,如果有一部分数据没有被训练到,就只能对这份数据进行暴力搜索,QPS 就会大幅度的下降,这显然是不可接受的。基于图的索引可以支持一些在线的增量构建,但是需要内存维护图的结构才能进行快速的查找,这与数据湖 serverless(无服务器)的概念不匹配,因为数据湖都是 serverless 的,没有一个进程能够去维护复杂的内存的状态。并且图在分布式环境下做查询,实现难度也是很大的。所以索引技术无法直接使用。
并且数据湖都是 immutable 的,在每一个 immutable 内存文件下,无法实现前面提到的这两类索引结构。
另外一个问题是,目前很多主流的向量数据库更加侧重于 search 的操作,并没有优化 join。Join 和 search 的主要区别在于,search 偏向于在线的场景,是交互式的,需要在非常短的时间内返回结果。另外一类是批量检索,用户需要定时做大规模的计算,目前的向量数据库对此并没有特别进行优化,或者说支持的范围非常有限,并且会存在读放大的情况。每次查询索引读取到的数据都有可能会重复,性能很差。这在苹果的一篇论文中有提到,苹果的做法是把很多的点查询进行了合并,本质上是转化成了一个 join 去执行。
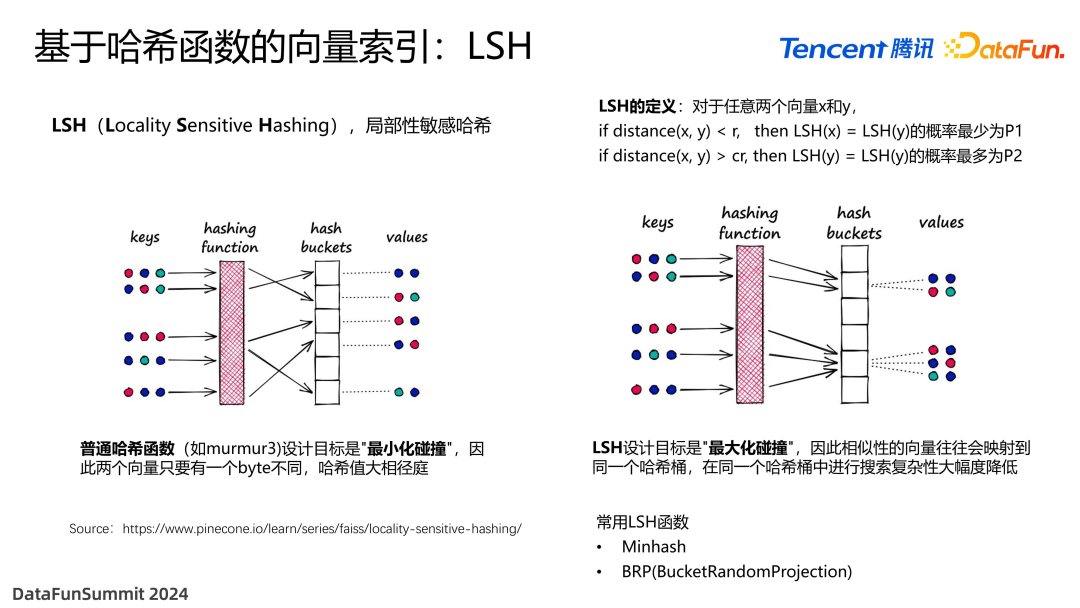
为了解决这个问题,我们采用了另外一类基于哈希的向量索引技术,即 LSH(Locality Sensitive Hashing),局部性敏感哈希。普通哈希函数的设计目标是最小化碰撞,两个向量只要有一个字节不同,映射的哈希值就完全不一样。但这与向量检索的定义是相反的,向量检索是需要两个相似的向量映射在一个地方。而 LSH 与普通哈希函数是完全相反的,其设计目标是最大化碰撞,也就是通过数学公式去保证如果两个向量的距离很接近,那么其映射到的哈希值是一样的。我们在哈希值一样的向量当中去找,能大幅度提高搜索的效率。最常用的 LSH 有 Minhash、BRP,这也是 Spark 自带的算法,但并没有跟存储层挂钩,所以这个索引都是在运行当中生成的。
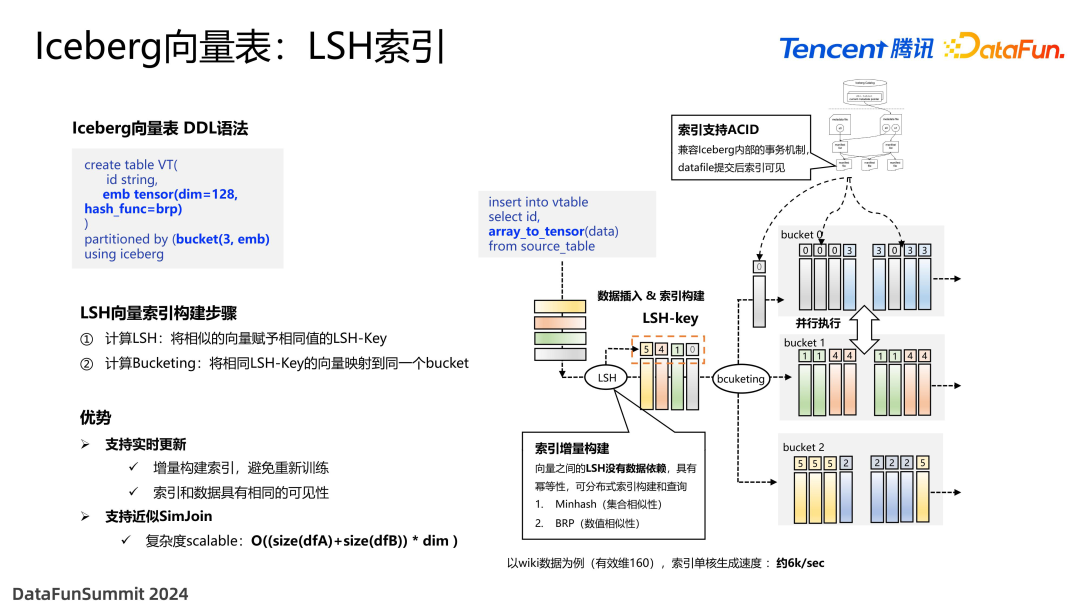
Spark 在运行当中生成索引会有非常大的计算开销,因此我们思考能否将其放到存储层去做,这样只需要做一次,后面的查询都可以受益。为此引入了 Iceberg 向量表的优化。如图是建向量表的语法,自定义的数据类型 tensor 可以指定向量维度,比如 128 维,指定哈希函数为 BRP,还可以设定 bucket 的数量,再使用 Iceberg 作为存储。
如上图右侧所示,以数据插入为例来介绍如何构建 LSH 索引。首先提供了在 Spark 中注册的 UDF(array_to_tensor),用户写入 SQL 时,将数据读取到内存当中计算附加列,这个列就是使用 LSH 函数计算得到的,如图计算出了 0145 这样一个整数,再进行 bucketing,这是 Iceberg 自带的一个分桶技术。在经过 bucketing 之后会再进行 distribute,把对应的向量写入到对应的 bucket 当中,这样的好处就在于可以发现相同哈希值的数据都在一个桶当中,所以搜索范围就受到了约束,在分布式下计算更加有优势。
有细心的同学可能会注意到,这里的向量索引构建跟前面向量数据库索引的区别就在于,构建是没有向量之间的数据依赖的,也就是每条数据可以直接通过这个函数来计算出它的 LSH 值,所以每条值可以并行计算,非常适合数据湖这样大规模的场景。并且索引写在每个 data file 中,在 data file 被 commit 之后索引就立即可见了,不会有延迟问题,从而实现了增量索引的构建,写入之后索引立即可查。
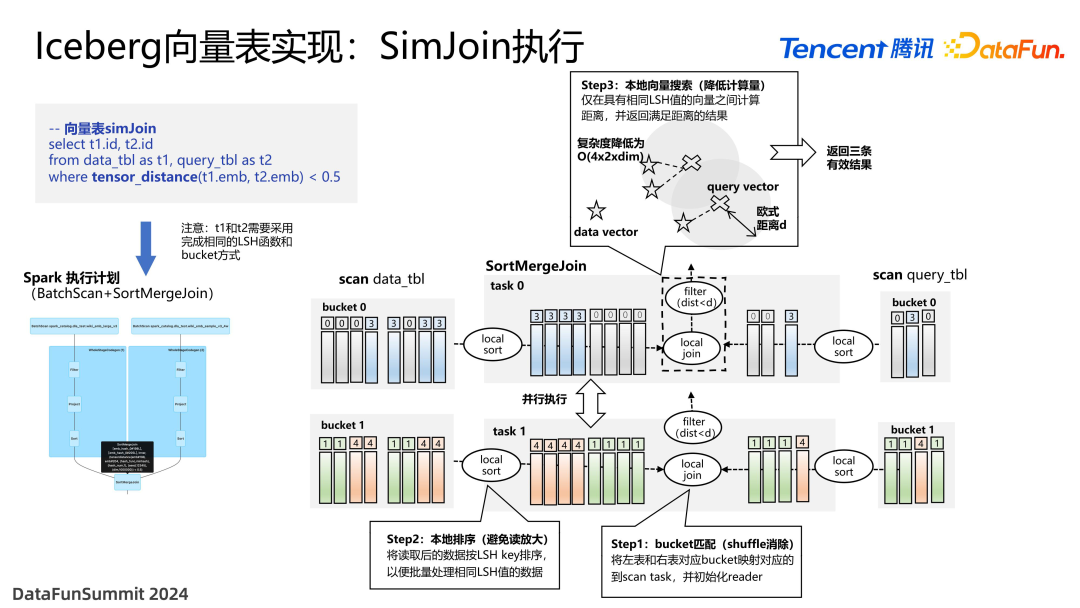
前面介绍了向量数据如何写入,接下来介绍如何查询。查询方面提供了一个函数叫做 tensor_distance,可以让用户指定两个向量之间的距离,比如 <0.5。这样做的前提是两张表要采用相同的 LSH 函数和 bucket 方式。Join 的过程是利用 Spark 来实现的,执行计划是 BatchScan + SortMergeJoin。
执行过程如上图所示。第一步是 bucket 匹配,目的是让左表和右表中具有相同 bucket ID 的数据读取到同一进程当中,因为两张表采用相同的 LSH 和 bucket 方式,它们具有相同 LSH 值的数据是在同一个 task 当中的,因此这样的好处在于,通过这一步可以直接消除 shuffle 的过程。
第二步是进行 local sort。排序的原因是要将每个桶 当中具有相同 LSH 值的数据放到一起,这样的好处是可以进行批量查询,避免点查发生随机访问的问题。
第三步是进行本地向量检索,由于数据量已经被大幅度削减,计算复杂度是比较低的。并且每一个 bucket 在 Spark 当中都是可以并行执行的,因此查询也是可拓展性非常强的。
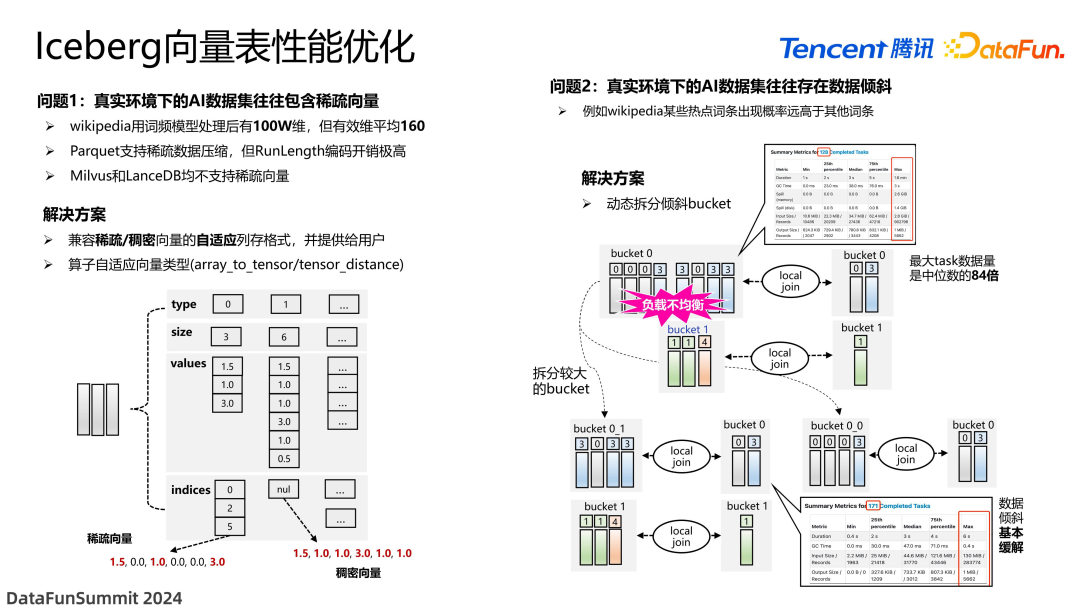
下面介绍我们在向量表实现过程中遇到的一些问题。第一个问题是真实环境中的 AI 数据集存在稀疏向量,比如 Wikipedia 用词频模型处理之后有 100 万维的数据,其中有效维度非常低。对于这种数据,如果直接存储,代价非常大。虽然可以进行压缩,但压缩的计算开销非常高。市面上主流的向量数据库都不支持存储这种稀疏向量。因此我们需要实现一个能够自适应支持向量稠密和稀疏两种状态的自定义的格式,来提高存储性能。
上图左下方展示了这种存储格式的结构,每条向量被拆成了多个字段,第一个字段是它的 type,用 0 和 1 来区分它是稠密还是稀疏的;第二是 size,记录这个向量有多少条真实有效的数据;第三个字段就是数据本身,对于稀疏向量,是不存储它们为 0 的数据的;第四是索引,记录了这个向量哪些数据是有效的,记录有效的位置,对于无效的数不存储,对一些稠密向量来说,这个字段就是一个空值。这样我们就可以用同一个数据结构支持两种不同类型的数据格式,这也是受到了 Spark 内存存储格式的启发。
我们也实现了两种算子,array_to_tensor 和 tensor_distance。这两种算子可以自动识别每条数据的格式到底是哪一种,来选择对应的正确的函数进行求解。
另外一个问题是我们发现很多真实数据存在非常严重的数据倾斜的问题。比如某些词条的热度非常高,远高于其他词条的热度。这样会导致某些桶非常大,比如图中的 bucket 0 比下面的 bucket 1 大很多,这一个桶的执行时间远远长于其他桶,会导致整体的性能被拖累。我们使用了动态拆分 bucket 技术,这也是 Spark AQE 加上 bucket join 的结合,是 Spark 3.5 自带的特性,我们把它移植到了低版本的 Spark 当中。如图所示,将大的 bucket 0 拆分成了 0_1 和 0_0 两个桶,对另外一些比较小的表进行复制操作,这样就缓解了负载不均衡的问题,从而真正发挥了向量查询的优势。
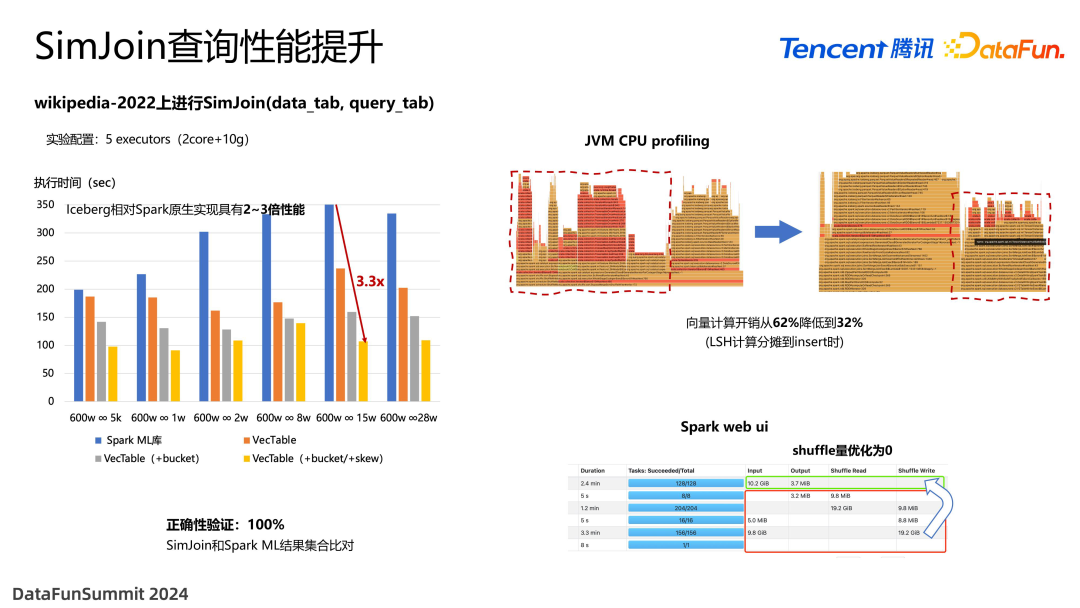
我们对比了 Iceberg 向量表 SimJoin 查询与 Spark ML 的性能,可以看到 2 到 3倍的提升,最高有 3.3 倍。再用 profiling 时间来分析提升到底在哪里。第一个是计算性能的开销,因为 LSH 是向量维度高度相关的操作,计算量非常大,我们在构建索引时已经把值计算好,所以在查询时只需要进行距离计算,就不需要再进行哈希函数的计算了。另外还有 shuffle 的开销,在原始的 Spark 当中有大量 shuffle 操作,因为它需要将具有相同哈希值的数据进行重分布操作。但是我们是在写入的时候就进行了重分布,所以在查询时 shuffle 量变成了 0,shuffle 的开销就消除了。由于这两部分的优势,带来了整体上的性能提升。同时为了保证正确性,我们与 Spark 的执行结果进行了对比,发现结果是完全一致的。