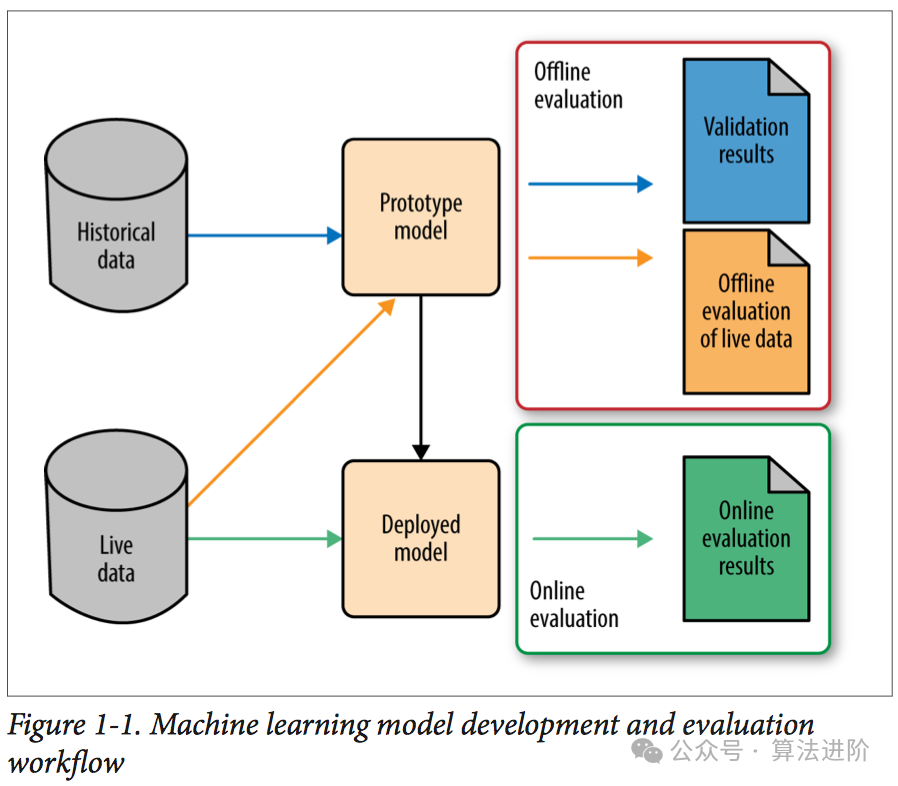
机器学习模型的种类繁多,应用广泛,如下列举一些常用模型:
1、线性模型
-
线性回归(Linear Regression) -
逻辑回归(Logistic Regression)
2、基于树的模型
-
决策树(Decision Tree)
-
随机森林(Random Forest)
-
梯度提升决策树(Gradient Boosting Decision Tree, GBDT)
-
LightGBM
-
XGBoost
3、神经网络模型
-
深度神经网络(Deep Neural Network, DNN)
-
卷积神经网络(Convolutional Neural Network, CNN)
-
循环神经网络(Recurrent Neural Network, RNN)
-
Transformer
-
GAN
-
diffusion model
4、支持向量机
-
支持向量机(Support Vector Machine, SVM)
5、近邻模型
-
K近邻(K-Nearest Neighbors, KNN)
6、概率图模型
-
朴素贝叶斯(Naive Bayes)
-
贝叶斯网络(Bayesian Network)
-
隐马尔可夫模型(Hidden Markov Model, HMM)
7、集成学习模型
-
AdaBoost
-
XGBoost
-
LightGBM
8、聚类模型
-
均值聚类(K-Means Clustering)
9、降维模型
-
主成分分析(Principal Component Analysis, PCA)
10、其他模型
-
线性判别分析(Linear Discriminant Analysis, LDA)
-
关联规则学习(Association Rule Learning)
-
矩阵分解(Matrix Factorization)
-
协同过滤(Collaborative Filtering)
在众多机器学习模型中,我们如何在各种实际情况下做出恰当的选择呢?本文我从如下几个方面系统地分析下~ 有帮助的话点个赞哦。
1. 场景的角度
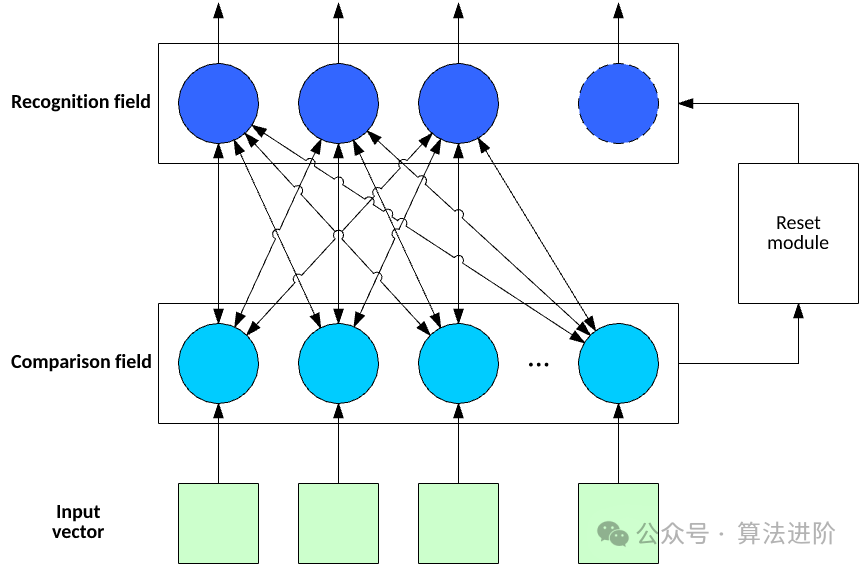
a. 图像识别
-
适用模型:卷积神经网络(CNN) -
原因:CNN能够自动从原始图像中提取有效的特征表示,适用于处理复杂的图像数据。其层次化的结构可以捕捉图像中的局部到全局的信息,对于图像识别任务具有很高的准确度。 
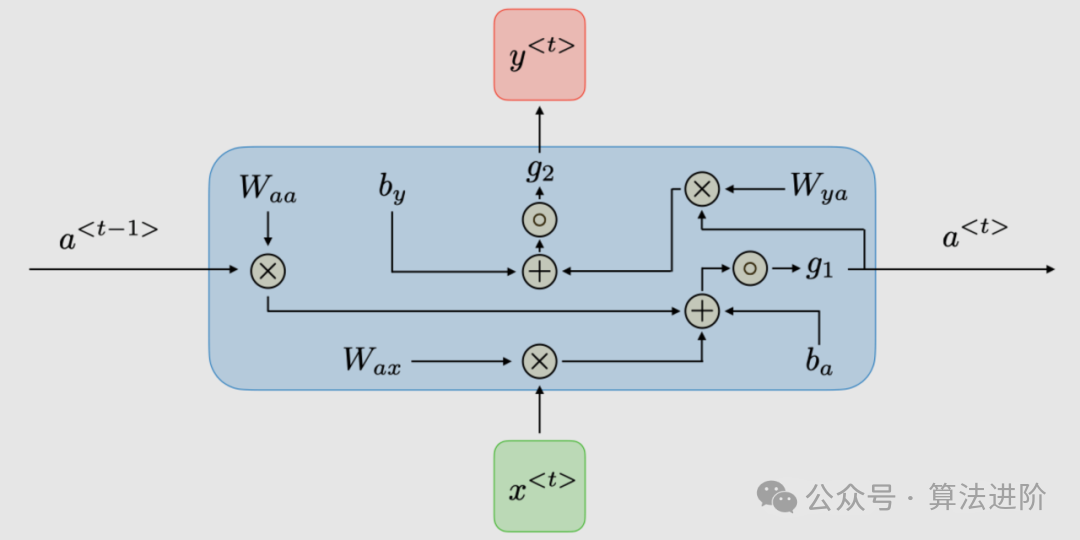
b. 自然语言处理
-
适用模型:循环神经网络(RNN)、Transformer(如BERT、GPT等) -
原因:RNN可以处理序列数据,捕捉文本中的上下文信息。而Transformer模型通过自注意力机制,能够同时考虑文本中的前后文信息,对于长文本和复杂任务有更好的性能。
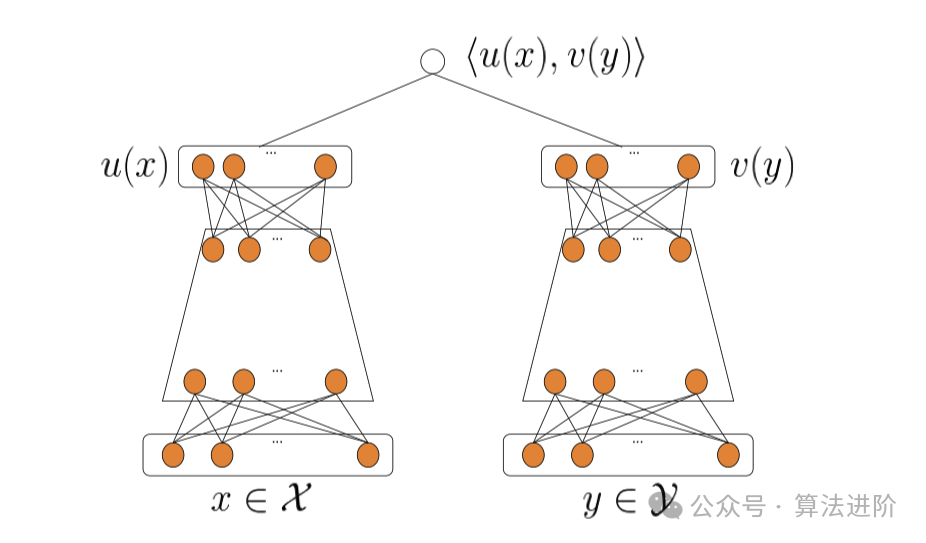
c. 推荐系统
-
适用模型:协同过滤、基于内容的推荐、深度学习推荐模型 -
原因:协同过滤基于用户或物品之间的相似性进行推荐,简单有效。基于内容的推荐则根据用户的历史行为和兴趣进行推荐。深度学习推荐模型能够自动学习用户和物品之间的复杂关系,提供更个性化的推荐。
d. 表格数据的任务
适用模型:自然语言及图像识别上面深度学习无疑是王者,但在表格类异构数据上,xgboost等集成学习树模型才是实打实的神器。大量实验表明基于树的模型在中型表格数据集上仍然是 SOTA。
对于这一结论,下文给出了确凿的证据,在表格数据上,使用基于树的方法比深度学习(甚至是现代架构)更容易实现良好的预测,研究者并探明了其中的原因。
论文地址:https://hal.archives-ouvertes.fr/hal-03723551/document

2. 可解释性的角度
-
高解释性需求:决策树、线性模型 -
决策树生成的规则易于理解,可以直观地展示决策过程。 -
线性模型通过系数可以清晰地展示每个特征对预测结果的影响。 -
低解释性需求:深度学习模型 -
深度学习模型虽然解释性相对较弱,但可以通过一些技术(如特征重要性评估、注意力机制等)来提高其解释性。
3. 预测标签
-
分类问题:逻辑回归、支持向量机(SVM)、集成学习、神经网络 -
根据问题的复杂性和数据的规模选择合适的模型。例如,对于线性可分的问题,逻辑回归可能是一个好的选择;对于非线性问题,神经网络可能更有优势。 -
回归问题:线性回归、岭回归、支持向量回归(SVR)、集成学习、神经网络 -
这些模型适用于预测连续值的任务,根据数据的特征和问题的需求选择合适的模型。 -
无监督问题:聚类、PCA、embedding等 -
这些模型适用于无标签的聚类、降维、表示学习等任务;
4. 数据规模与特征情况
-
小数据集:决策树、朴素贝叶斯、支持向量机(SVM) -
这些模型在小数据集上表现较好,能够避免过拟合。 -
大数据集:深度学习模型、随机森林 -
深度学习模型能够处理大规模的数据,并通过复杂的网络结构捕捉数据中的细微差异。随机森林也能够处理大数据集,并且具有较好的鲁棒性。 -
特征数量与类型:根据特征的数量和类型选择合适的模型。例如,对于高维稀疏数据,可以选择使用稀疏模型如稀疏线性模型、支持向量机等。 -
在线学习:值得一提的事,如果业务数据变化等情况,有在线学习迭代模型的需求,选择深度学习模型是一个不错的选择。
5. 计算资源及时间
-
资源有限:选择计算效率较高的模型,如线性模型、决策树等。 -
资源丰富:对于复杂的任务,可以选择深度学习模型,虽然训练时间较长但性能更优。
6. 模型效度
很多时候模型效度需要实际验证的时候才知道优劣,通常情况下那个模型效度好,才是最终决定我们选择那种模型,或者考虑所有模型一起上(模型融合)。
模型融合:是一种结合多个模型的预测结果以生成更强大、更准确的预测结果的策略。它通过将多个弱模型(基模型)的预测结果整合,以降低误差并提高模型的泛化能力。常见的模型融合方法,如Bagging、Stacking与Boosting。
常用的效度评估指标如下:
-
分类评估指标:准确率、召回率、F1分数等。 -
回归评估指标:均方误差(MSE)、均方根误差(RMSE)、R平方等。