
>>>本系列视频课程已在我的B站(🔍唐国梁Tommy)上线,复制以下链接或点击文末“阅读原文”即刻开始学习。
【Agent Skills 实战教程:如何让 Agent 按需加载知识?渐进式披露完整流程|Agno Skills工作流全链路解析】
https://www.bilibili.com/video/BV1yUfnBjEu2/?share_source=copy_web&vd_source=44de46517e4609888d4085939ef749f4
你可能也遇到过这类问题:
-
同样的任务,每次都要重新把规则讲一遍; -
让 AI 写周报、写报告、做评审,输出风格忽左忽右; -
团队里每个人都在写提示词,但没人能稳定复用别人的方法。
如果你想让 AI Agent 从“会聊天”变成“能干活、可交付、可迭代”的生产力系统,Agent Skills 是最关键的一块拼图。
Skill 到底是什么?
先给一个最简定义:
Skill = 可发现、可按需加载的任务 SOP 模块(能力包)。
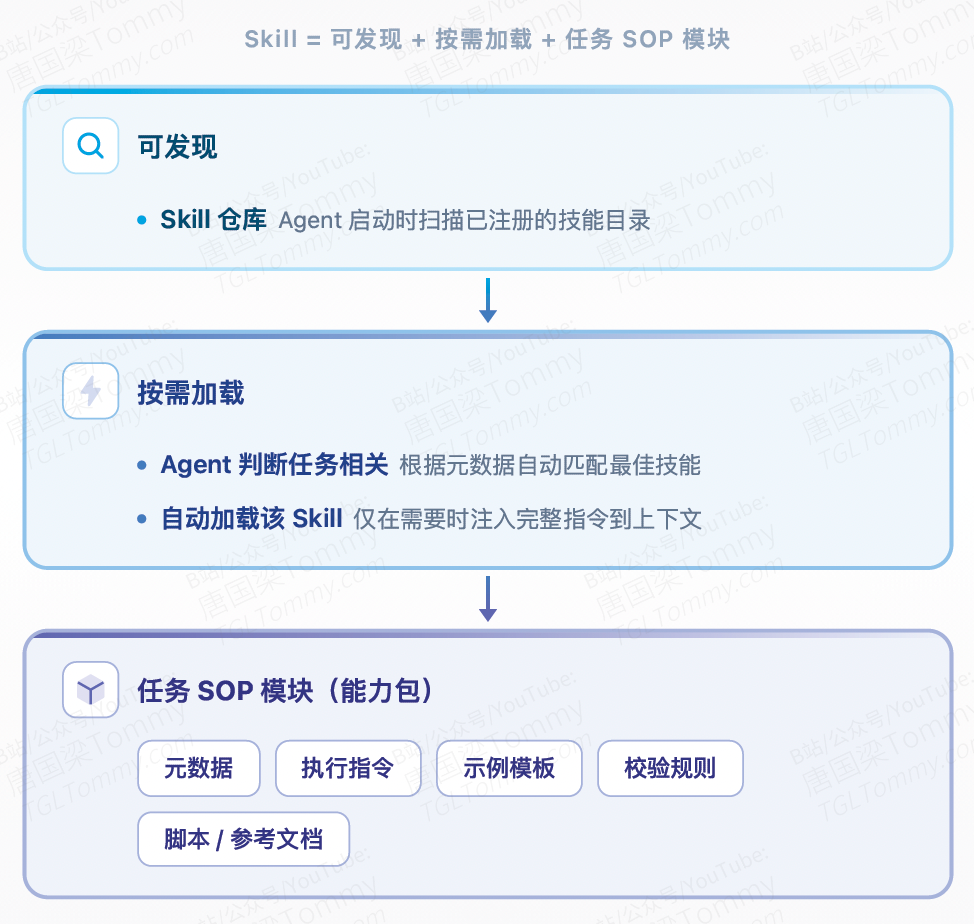
它不是一段提示词,它是一个产品化的能力单元——包含了元数据、执行指令、示例模板、校验规则,甚至可以带脚本和参考文档。
用 Anthropic 官方的话说:Skills 是用于扩展 AI Agent 功能的模块化能力包。每个技能以文件夹形式存在,包含指令、元数据和可选的资源文件。当 Agent 判断某个技能与当前任务相关时,会自动加载并使用。
和 Prompt 的核心差别(左滑查看)
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一句话总结:Prompt 是便签纸,Skill 是员工手册。
Skill 解决的不是“写作”,而是 3 个长期痛点

-
反复解释规则——每次新对话都要重新告诉 AI “请遵循以下格式”。有了 Skill,触发即加载,不用重复。 -
输出风格不稳定——同样的任务,今天输出 A 格式,明天变 B 格式。Skill 内置模板和校验清单,输出更稳。 -
团队流程无法复用——小王写的提示词小李用不了。Skill 标准化后,团队共享一套能力包。
一个直观的例子
假设你经常做 “某个热点方向的研究报告(调研→对比→结论→路线图)”:
没有 Skill 的时候:
“请帮我做一份研究报告。要求:先给出 1 页 TL;DR;再按‘背景/问题定义/技术路线/关键论文与方法对比/数据与评测/落地应用/风险与局限/未来趋势’分章节;对每条路线给优缺点表格;最后给 3 条可执行建议和一个 90 天路线图。写作要偏工程落地,不要空泛,还要保留引用格式……”
每次都要把报告结构、对比维度、写作口径、交付物格式重新讲一遍,稍不注意就会变成“堆概念、没结论”。
有 Skill 的时候:
/research-report [主题] [目标读者] [时长/深度]
一句话搞定。因为所有规则已经封装在 Skill 里:
-
自动生成目录与对比框架(路线、指标、数据集、成本、风险) -
强制输出“结论先行 + 可执行建议 + 路线图” -
统一引用与表格模板(避免风格漂移)
金句:Skill 的本质,是把个人经验变成组织资产。
Prompt / Tool / Skill / MCP 区别
很多人卡在这里:到底什么时候用 Prompt?什么时候用 Tool?MCP 又是什么?
很多人搞不清 Prompt、Tool、Skill、MCP 这四个东西的边界。
一个清晰的四分法:
-
Prompt:临时指令(口头交代) -
Tool:一个动作/接口(像一把锤子) -
MCP:外部系统接入协议(“去哪里拿数据、调什么 API”) -
Skill:可复用 SOP 包(员工手册:遇到这种事该怎么做)
四个角色(左滑查看)
|
|
|
|
|
|---|---|---|---|
| Prompt |
|
|
|
| Tool |
|
|
|
| MCP |
|
|
|
| Skill |
|
|
|
MCP 🆚 Skill
Skill 负责 How(流程与规范),MCP 负责 What/Where(数据与动作)。
两个秒懂场景
场景 1:”帮我生成本周周报”
这更像 Skill。因为你需要的是一套固定流程:
*先从任务记录里提取本周完成的事项
*按模板分”本周完成 / 下周计划 / 风险事项”三段
*输出格式是 Markdown,口吻要职业化
这些”怎么做”的规范,就是 Skill 的活儿。
场景 2:”从 Jira 里拉取本周的任务列表”
这更像 MCP。因为你需要的是:
*连接到 Jira 的 API
*用我的账号鉴权
*拉取指定时间范围的 ticket
这些”去哪里连、拿什么数据”,就是 MCP 的活儿。
详细对比表(左滑查看)
|
|
|
|
|---|---|---|
| 定位 |
|
|
| 实现方式 |
|
|
| 部署 |
|
|
| 交互 |
|
|
| 适用场景 |
|
|
它们是互补关系
最强大的组合是:MCP 提供数据和工具 → Skill 提供 SOP → Agent 执行闭环。
比如:
-
MCP 连接 Arxiv 拉取论文与引用 → Skill 自动生成“研究报告” -
MCP 读取 Git 仓库的实验代码与配置→ Skill 输出“复现实验复盘报告” -
MCP 拉取内部知识库/会议纪要/数据看板 → Skill 产出“季度技术洞察报告”
金句:Skill 教 AI 怎么干活,MCP 帮 AI 连接世界。
为什么 Skill 会更稳?核心原理:按需加载(渐进式披露)
Skill 的关键不是“写得长”,而是“不要一次性塞满上下文”。
用“渐进式披露(Progressive Disclosure)”来解释:
需要什么给什么,不需要的不加载。
三层加载模型
为什么这比”全塞进去”好?
传统方式(全量加载):
-
假设你有 50 个工具/技能 -
预加载所有定义 → 约 72,000 tokens -
加上对话历史和系统提示 → 约 77,000 tokens -
还没开始干活,上下文就用了大半
Skills 按需加载方式:
-
启动时只加载元数据 → 约 5,000 tokens(50 个技能 × 100 tokens) -
激活 1 个技能 → 加载约 3,000-5,000 tokens -
总计约 8,000-10,000 tokens
这是 85% 的 token 节省!
而且不只是省 token——准确率也提升了。根据 SkillPort 的测试数据:
-
Claude Opus 4:准确率从 49% 提升到 74% -
Claude Opus 4.5:准确率从 79.5% 提升到 88.1%
错误示范 vs 正确做法
❌ 错误示范:把 3,000 行编码规范直接塞进 system prompt
-
AI 上下文被塞满,注意力被稀释 -
存在”迷失在中间”现象——中间位置的信息最容易被忽略 -
输出开始发散,该遵守的规则没遵守
✅ 正确做法:把规范封装成 Skill
-
平时只占 100 tokens(名称 + 描述) -
触发时才加载核心指令(~5,000 tokens) -
需要详细参考时再加载 references/ -
输出稳定,因为 AI 的注意力集中在当前任务相关的规范上
技能选择机制
一个很关键的设计细节:Skills 的选择完全靠 LLM 自身的推理能力,没有算法路由,没有意图分类器,没有语义搜索。
流程是这样的:
-
系统把所有技能的 name + description 格式化成文本,放入 Skill 工具的描述中 -
用户发来请求 -
LLM 阅读请求,对比所有技能描述,自主判断该用哪个 -
决定后,通过内部的 “Skill” 工具调用,加载该技能的完整内容
这意味着:description 写得好不好,直接决定了你的 Skill 能不能被正确触发。
金句:三层加载 = 最小信息做判断 + 按需加载做执行 = 省上下文 + 更稳定。
手把手教你写第一个Skill
Skill 的最小形态其实很朴素:一个文件夹 + 一个 SKILL.md 文件(左滑查看)
my-skill/
└── SKILL.md ← 这一个文件就够了复杂一点的 Skill 可以有更多文件:(左滑查看)
my-skill/
├── SKILL.md # 必需:技能定义
├── scripts/ # 可选:可执行脚本
│ └── validator.py
├── references/ # 可选:详细参考文档
│ └── REFERENCE.md
└── assets/ # 可选:模板和静态资源
└── template.mdSKILL.md 的两部分
SKILL.md 由两部分组成:
第一部分:YAML Frontmatter(元数据区)(左滑查看)
name: agent-design-reviewer
description: >
用于生成“Agent 系统设计评审包”。当用户提供一个 Agent 项目想法或现有方案
(目标、工具、数据源、约束、指标)时使用;自动输出:系统架构图、模块拆解、
风险清单、评测方案与里程碑计划。不适用于单纯写代码或逐段翻译说明文档。
---第二部分:Markdown 正文(执行指令区)(左滑查看)
## 执行步骤
1. 需求澄清:目标用户/核心任务/输入输出/成功指标(若缺失先列出缺失项)
2. 任务分解:把目标拆成 3-7 个子任务(可工具化/可评估)
3. 架构设计:输出端到端架构(Agent Loop:Think→Plan→Act→Observe→Reflect)
4. 模块拆解:Planner / Tools / Memory / Retriever / Evaluator / Guardrails
5. 风险与边界:失败模式(幻觉、工具误用、权限、数据泄露、成本、延迟)
6. 评测方案:离线集 + 在线集 + 指标(成功率/成本/时延/引用正确率/鲁棒性)
7. 交付计划:30/60/90 天里程碑(PoC→MVP→Prod),每阶段验收标准
## 输出模板
### TL;DR(10 行内)
- 做什么:
- 给谁用:
- 成功标准:
- 关键差异点:
### 架构图(Mermaid)
```mermaid
flowchart LR
U[User] --> P[Planner]
P --> T[Tool Router]
T -->|Call Tools| X[(Tools/MCP)]
X --> O[Observe]
O --> M[Memory/Retrieval]
M --> P
P --> A[Answer]
## 模块清单(职责与接口)
模块 输入 输出 关键设计点 可替代方案
## 风险清单(Failure Modes)
- 幻觉风险:如何降低(证据引用/自检/多样性采样)
- 工具风险:参数错误/误调用(权限分级/工具白名单)
- 成本风险:token/工具调用频率(缓存/批处理/早停)
- 数据风险:敏感信息(脱敏/审计/最小权限)
## 评测与验收
- 离线:固定测试集(任务成功率、引用正确率、步骤长度、成本)
- 在线:A/B(用户满意度、完成时长、复访率)
- 失败回放:日志字段规范(trace_id、tool_calls、evidence)
## 30/60/90 天计划
- 30 天:PoC(核心链路跑通 + 基线指标)
- 60 天:MVP(覆盖主要任务 + 失败回放闭环)
- 90 天:Prod(权限治理 + 监控报警 + 成本优化)YAML 字段详解(左滑查看)
|
|
|
|
|---|---|---|
name |
|
/name 斜杠命令 |
description |
|
|
allowed-tools |
|
"Read,Write,Bash" |
model |
|
|
version |
|
|
disable-model-invocation |
|
/name 调用 |
description 写作公式
description 是决定触发率的关键。推荐用这个公式:
当用户要做【任务 A / 任务 B】并且需要【输出格式/目标】时使用;当【反例场景】不要使用。
✅ 好的 description 示例:(左滑查看)
description: >
从 PDF 文件中提取文本和表格,填写 PDF 表单,合并多个 PDF。
当需要处理 PDF 文档或用户提到 PDF、表单、文档提取时使用。❌ 差的 description 示例:
description: 帮助处理 PDF。差在哪?
-
没说清能做什么(提取文本?填表单?合并?) -
没说清何时用(什么场景触发?) -
太模糊,Agent 难以判断是否匹配
十行可运行示例
这是一个最简的可运行 Skill:(左滑查看)
---
name: code-explainer
description: >
用直观类比和 ASCII 示意图解释代码如何运行。
当用户问"这段代码怎么工作""帮我解释这个函数"时使用。
---
当解释代码时,请遵循以下步骤:
1. **类比说明**:先用日常生活中的事物作比喻
2. **绘制示意图**:使用 ASCII 图形绘制代码流程
3. **逐步讲解**:逐行解释代码执行过程
4. **提示注意**:指出一个常见的陷阱或误区
用对话的口吻给出解释,复杂概念可以使用多个类比。金句:name 决定你怎么调用它,description 决定 AI 什么时候自动用它。
把 Skill 当“产品”打磨:3 条黄金规则 + 1 个终局组合
会写 Skill 只是第一步,写好 Skill 才是关键。这里分享经过多个生产级项目验证的最佳实践。
三条黄金规则
规则 1:多给 examples(好结果长什么样)
这是 Supabase Agent Skills 项目总结出来的”对比学习模式”:
每条规则都要有”错误示范”和”正确示范”。
比如你写一个 SQL 优化 Skill,不要只说”应该用索引”,而是:
Incorrect (缺少索引导致全表扫描):(左滑查看)
SELECT * FROM orders WHERE customer_id = 123;
-- 没有索引时:Seq Scan,2500msCorrect (添加索引后的高效查询):(左滑查看)
CREATE INDEX orders_customer_id_idx ON orders (customer_id);
SELECT * FROM orders WHERE customer_id = 123;
-- 有索引后:Index Scan,2.3ms,提升 1087x为什么这么做?因为 AI 通过”对比”学得最快。看到了错误模式,它才能在用户代码中识别出同样的问题。
规则 2:把复杂内容下沉到 references
SKILL.md 正文建议控制在 5,000 tokens 以内。超出的内容放到 references/ 目录,在正文中用链接引用:(左滑查看)
## 详细规范
基础用法见上述步骤。更多高级配置请参阅:
- [表单处理指南](references/FORMS.md)
- [API Schema 说明](references/api-schema.json)这样 Agent 只在需要时才加载详细文档,不会一上来就塞满上下文。
规则 3:加输出校验清单
在 Skill 末尾加一个 checklist,让 Agent 在输出前自检:
## 输出校验清单
- [ ] 输出格式是否符合模板
- [ ] 是否包含所有必需字段
- [ ] 语气是否一致(口语化 vs 书面)
- [ ] 代码示例是否可运行
- [ ] 是否有遗漏的边界情况Anthropic 的四条开发指南
来自 Anthropic 官方 Skills 仓库的开发建议:
-
从评估开始——先在代表性任务上运行 Agent,观察局限性,再针对性地写 Skill -
结构化以支持扩展——SKILL.md 变臃肿时,拆分为独立文件;互斥内容保持分离 -
从 Claude 视角思考——监控 Agent 在实际场景中如何使用 Skill,关注意外的执行路径 -
与 Claude 协作迭代——让 AI 帮你把成功方法和常见错误捕获到 Skill 中
版本管理
像管理代码一样管理 Skill:
-
用 Git 做版本控制 -
在 YAML 中加 version字段 -
每次修改写 changelog -
重大改动升版本号
金句:Skill 的迭代方式更像写库/写组件,而不是写提示词。
真正能落地的形态:Skill × MCP = 生产级 Agent
最后是整套系统的“闭环组合范式”:
一句话:MCP 给 Agent 连上”手和眼”,Skill 给 Agent 装上”脑”。
给你的 3 个落地建议
-
从你最常做的“重复交付物”开始写 Skill
例如:研究报告、周报、技术评审、方案对比、复盘报告——越重复越值得封装。 -
先写一个“能跑通”的最小 Skill,再迭代
先做到“结构稳定 + 输出可验收”,再逐步加 examples、checklist、references。 -
最终目标不是写很多 Skill,而是形成组织资产库
用 Git 管理版本、写 changelog、统一分发,Skill 才会越来越值钱。
AI进阶
👉如果你想系统掌握多模态大模型前沿技术与应用,推荐你学习我的精品课程:
📚课程覆盖主流多模态架构、多模态Agent、数据构建、训练流程、评估与幻觉分析,并配套多个项目实战:LLaVA、LLaVA-NeXT、Qwen3-VL、InternLM-XComposer(IXC)、TimeSearch-R视频理解等,包含算法讲解、模型微调/推理、服务部署、核心源码解析。
💡本课程目前正在更新中,你可以在我的个人官网或B站课堂参与学习:
📺B站课堂(🔍唐国梁Tommy)https://www.bilibili.com/cheese/play/ss33184
🌐官网链接(国内访问需科学上网):https://www.tgltommy.com/p/multimodal-season-1
