
当你在给Agent接入Skills时,有没有遇到Skills并不是每次都有效的烦恼呢。
那么如何去验证Skills是否能在合适的时候触发?在编辑后效果是否提升?以及在新模型上是否依然有效?
针对这些问题,Anthropic敏锐地捕捉到了大家的痛点,将软件工程中严谨的「测试、基准跑分、迭代」理念引入到了skill-creator中,让非技术人员也可以去测试、衡量和优化Agent Skills。
Skills 分类与评测
目前,Agent Skills可以分成两类,这决定了为什么要测试它们:
能力提升型(Capability uplift skills)
这类Skills用来教大模型做它原来做不到或做不好的事情,比如极其复杂的PDF表格排版。
但是随着大模型能力越来越强,很可能模型自身就学会了这项能力,那么这类skill的评测主要用来判断,当前Agent接入的这个Skill还有没有存在的必要了。
偏好编码型(Encoded preference skills)
这类Skills主要是用来固化独有的SOP,比如你们公司的NDA审查流程、你每周从多个工具拉取数据进行汇总分析的业务流程。
这类Skills对于你和你团队来说很重要,评测主要是为了确保Agent能够严格遵守业务流程。
Skill Creator的三大利器
利器1:引入评测(Evals)
Skill-creator现在可以帮你做评测了!
你来为Skill定义测试标准,Skill-creator会帮你跑这份测试集,告诉你这项Skill是否合格。
主要有两个用途:及时发现质量退化、理解模型进展。
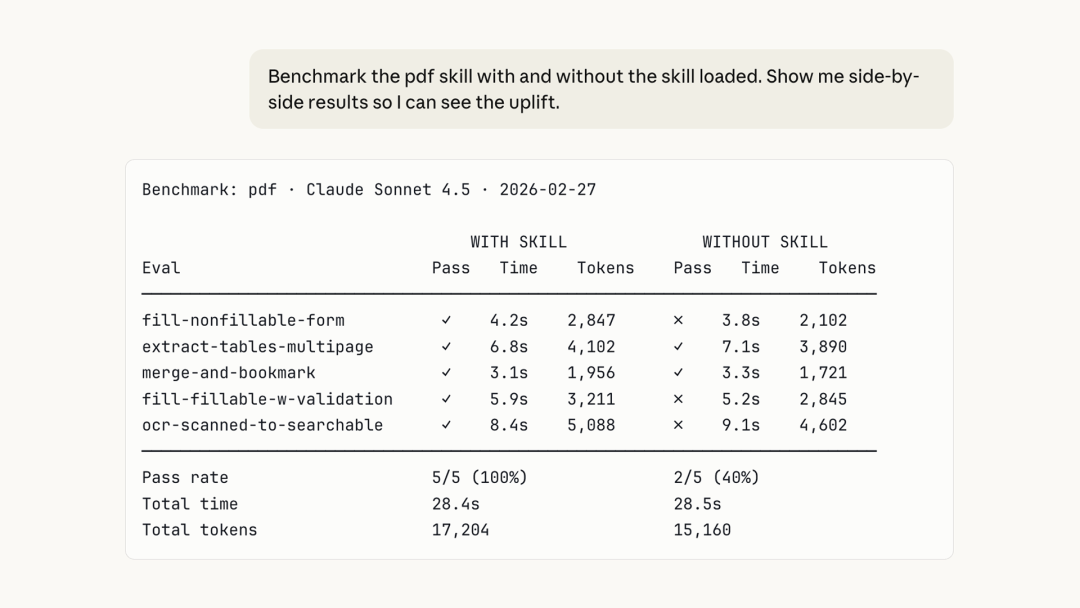
此外,在模型更新或迭代内容后跑一遍基准测试(Benchmark),它会跟踪评估通过率、耗时、token消耗量三个关键指标。
这些结果你可以集成到数据看板中,或关联到CI系统。
利器2:支持多智能体评测与 A/B 测试
以前线性运行评测速度慢,而且上下文容易互相污染。
现在skill-creator支持同时启动多个独立智能体并行跑测试,每个智能体都在干净独立的上下文中,拥有自己的Token和计时指标。
此外,还新增了做A/B测试的比较智能体。
用来对比两个版本skill,或者对比有skill和无skill,并在不知情的情况下,客观评判谁更好,从而你可以知道更改是否真的有帮助。

利器3:触发器调优(Trigger optimization)
Skill再厉害,如果大模型“想不起来用”也白搭。
随着Skill数量增多,描述的精准性变得至关重要:
-
如果描述太宽泛,会导致误触发;
-
如果描述太局限,则导致漏触发。
Skill Creator会自动分析你当前的描述和示例提示,并主动建议如何修改,以减少误触和漏触。
洞察评测与skill未来
目前Skills本质上是一份操作指南,告诉模型一步一步 How to do。
但随着大模型越来越聪明,Anthropic认为:Skill描述和测试标准的界限会逐渐消失。
未来,你只需要定义评测标准,告诉模型“什么样是好结果”,这个评测标准本身就会直接成为Skill的全部。
如何使用呢?
Claude.ai和Cowork中可以直接使用最新的skill-creator,Claude Code需要安装skill-creator插件。
