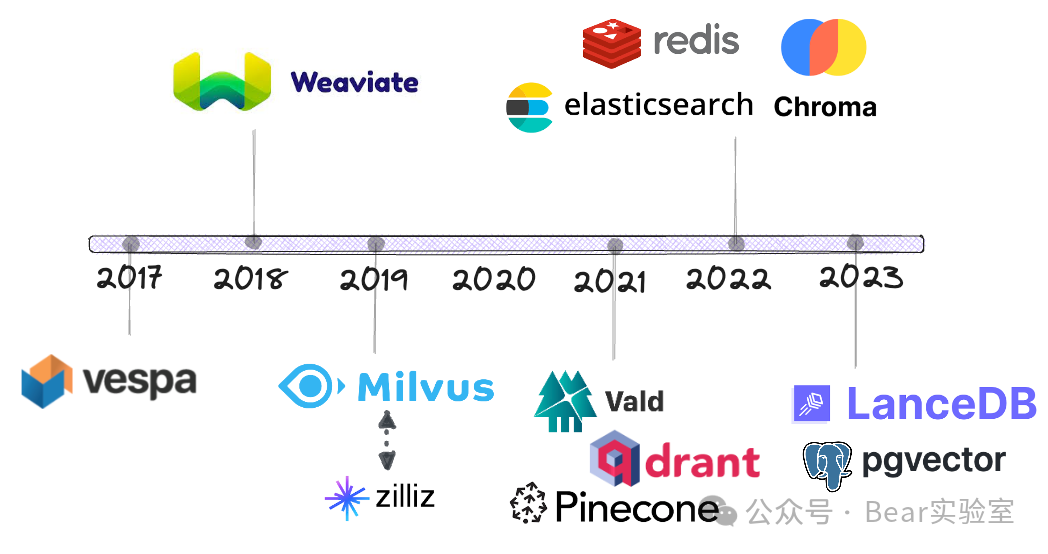
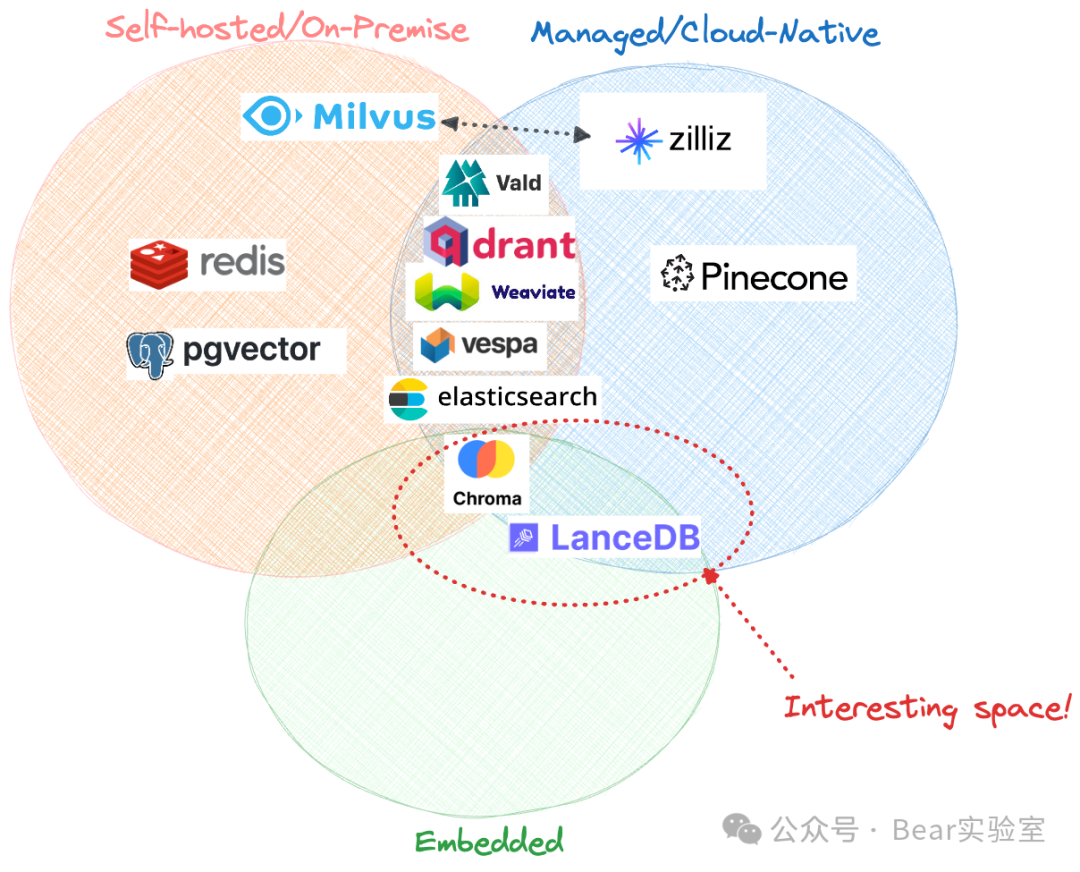
-
专用的向量数据库,原生就支持各种向量运算,如点积、余弦相似度等。这些数据库专为处理高维度数据而设计,能够应对大量查询请求,并能迅速完成向量间的相似性搜索。 -
支持向量的SQL数据库(例如pgvector),SQL数据库通过它们的向量支持扩展,提供了一种将向量数据整合到现有数据存储系统中的方式。这类数据库在构建索引和处理大量向量数据时性能表现并不理想,更适合于向量数据量较小(少于10万个向量)且向量数据仅作为应用程序的一个补充功能的场景。相反,如果向量数据是应用的核心,或者对可扩展性有较高要求,专用向量数据库就会是更合适的选择。 -
支持向量的NoSQL数据库(例如Redis),NoSQL数据库中新增加的向量支持功能尚属初级阶段,且尚未经过充分的时间验证。 -
全文搜索数据库(例如ElasticSearch)能支持比较全面的文本检索和高级分析功能。但是当涉及到执行向量相似性搜索和处理高维度数据时,它们与专门的向量数据库相比就不够强了。这些数据库往往需要与其他工具搭配使用才能实现语义搜索,因为它们主要依赖于倒排索引而不是向量索引。
-
混合搜索还是关键词搜索?关键词 + 矢量搜索的混合搜索可产生最佳结果,每个矢量数据库供应商都意识到了这一点,并提供了自己的定制混合搜索解决方案 -
本地部署还是云原生?许多供应商大力推销“云原生”,好像基础设施是世界上最大的痛点,但从长远来看,本地部署可能更经济,因此也更有效 -
开源还是完全托管?大多数供应商都基于源代码可用或开源代码库构建,以展示其底层方法,然后将管道的部署和基础设施部分货币化(通过完全托管的 SaaS)。仍然可以自行托管其中许多,但这需要额外的人力和内部技能要求。