

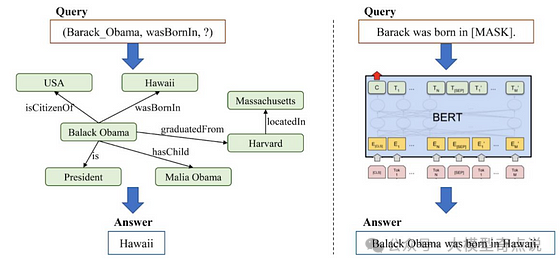
-
幻觉:大型语言模型有时会产生令人信服但不正确的信息。相反,知识图谱提供基于其事实数据源的结构化和明确的知识。 -
推理能力有限:大型语言模型难以理解和使用支持证据来得出结论,特别是在数值计算或符号推理方面。知识图谱中捕捉的关系允许更好的推理能力。 -
缺乏领域知识:虽然大型语言模型在大量通用数据上进行训练,但它们缺乏特定领域的知识,如医学或科学报告中的特定技术术语。与此同时,可以为特定领域构建知识图谱。 -
知识过时:大型语言模型训练成本高昂且不经常更新,导致它们的知识随时间变得过时。另一方面,知识图谱有一个更直接的更新过程,不需要重新训练。 -
偏见、隐私和毒性:大型语言模型可能会给出有偏见或冒犯性的回答,而知识图谱通常建立在没有这些偏见的可靠数据源之上。
-
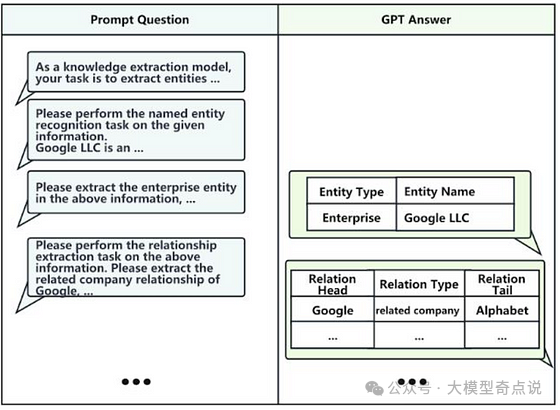
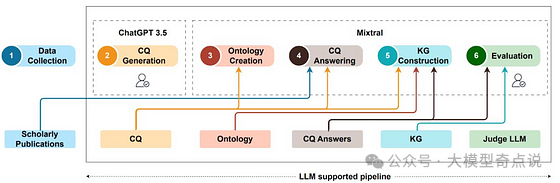
使用LLMs辅助自动构建知识图谱:LLMs可以从数据中提取知识以填充知识图谱。关于此方法的更多细节将在下面讨论。 -
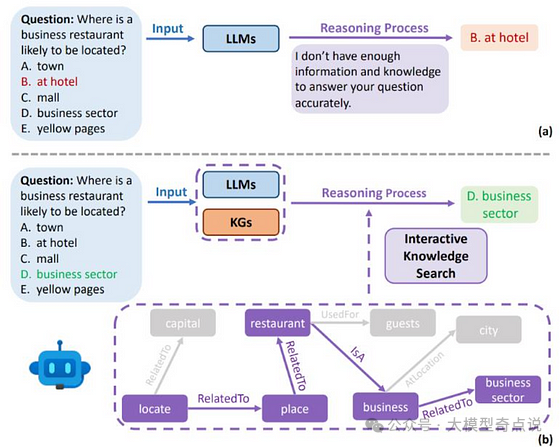
教导LLMs从知识图谱中搜索知识:如下图所示,知识图谱可以增强LLMs的推理过程,使LLMs能够得出更准确的答案。 -
将它们结合成知识图谱增强的预训练语言模型(KGPLMs):这些方法旨在将知识图谱纳入LLMs的训练过程中。
-
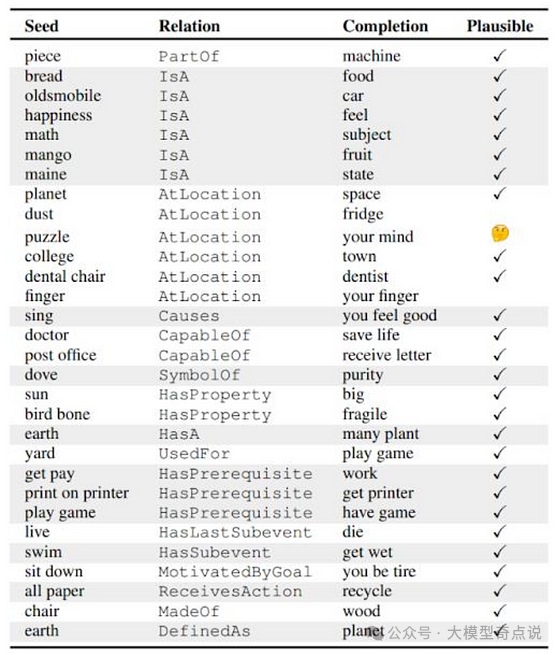
关系可能很复杂,例如,“A 有能力,但不擅长 B”。 -
关系可能涉及两个以上的实体,例如“A 可以在 C 处执行 B”。
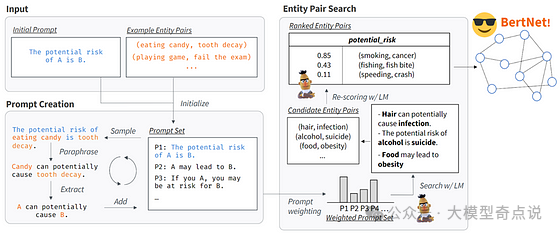
LLMs构建知识图谱的优势包括:1.表示复杂关系;2.提升关系质量;3.易于更新和扩展;4.增强知识可解释性;5.实现知识多样性和全面性;6.减少人工干预。
