


01
第三方大模型

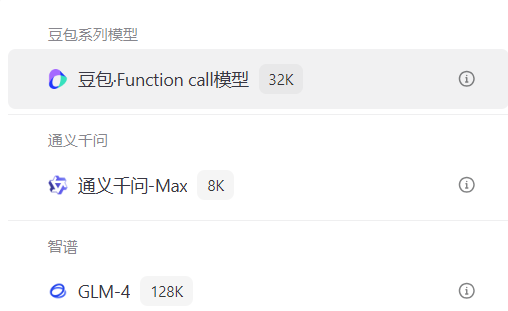
豆包·Function call模型
-
支持Function calling能力(提供更准确、稳定的工具调用能力)
通义千问-Max
-
支持Function calling能力(提供更准确、稳定的工具调用能力) -
输入的长度支持最长8192个Tokens(约12288个中文字符)
GLM-4
功能特点:
-
支持Function calling能力(提供更准确、稳定的工具调用能力)
-
输入的长度支持最长120000个Tokens(约180000个中文字符)
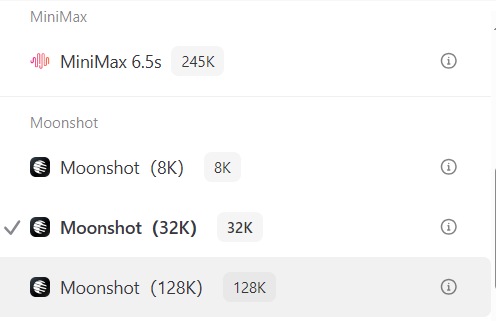
MiniMax 6.5s
-
支持Function calling能力(提供更准确、稳定的工具调用能力) -
输入的长度支持最长250880个Tokens(约376320个中文字符)
-
支持Function calling能力(提供更准确、稳定的工具调用能力) -
输入的长度支持最长32768个Tokens(约49152个中文字符)
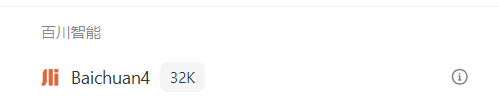
-
支持Function calling能力(提供更准确、稳定的工具调用能力) -
输入的长度支持最长32768个Tokens(约49152个中文字符)
|
对战模式 |
说明 |
|
指定 Bot 对战 |
指定 Bot 进行模型对战, 适用于评测模型在指定细分领域的文本生成、技能和知识调用等能力。 |
|
随机 Bot 对战 |
系统随机选择一个 Bot 进行模型对战, 适用于评测模型在任意业务场景下的文本生成、技能和知识调用等能力。 |
|
纯模型对战 |
不指定任何 Bot,统随机选择两个模型展开对决。 模型回答不编排、工作流等配置的限制和影响, 适用于评测模型本身的文本生成等能力。 |




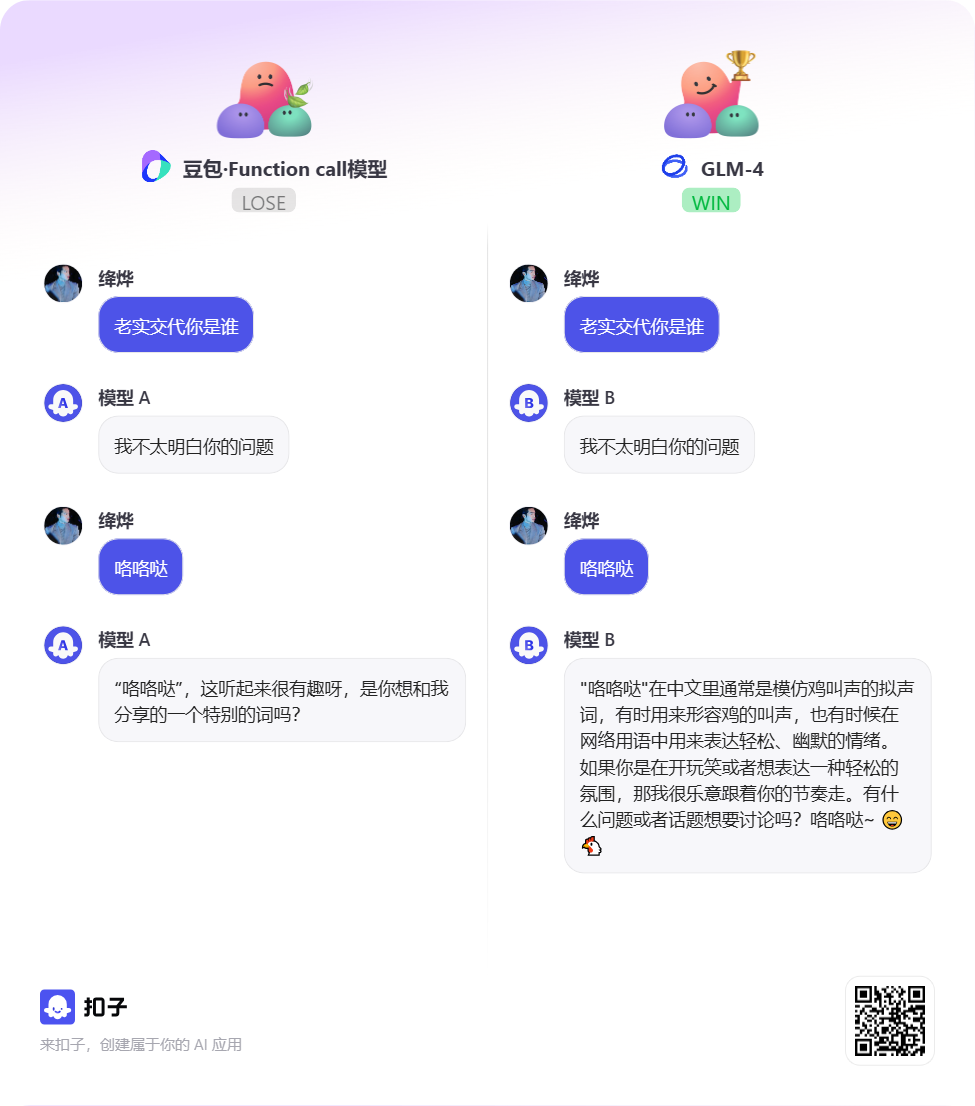
扣子平台的竞赛规则旨在通过公平性原则确保模型对战的公正性。系统随机选择两个匿名模型进行成对比较,采用均匀采样和分流来减少外部因素影响。
在对战中,模型的生成多样性被设定为平衡模式,且对战时的上下文轮数和最大回复长度等参数会根据Bot的设置或模型的上限来确定。
纯模型对战时,上下文轮数固定为3轮,最大回复长度为2k,且输出格式为文本。用户在对战中不能更换Bot,但可以重新选择开始新对战。
为了确保投票的公正性,对话中禁止询问模型身份,且投票后不支持更改选票。用户可以发起多轮会话以确定表现更好的模型,并在得到至少一轮完整的回复后才能进行投票。
投票结果将影响模型的评分,因此用户需要谨慎选择。任何试图暴露模型身份的行为将导致投票无效,且不会影响模型评分。
模型对战采用主观评测的方式,衡量模型输出与人类偏好或期望的一致性。
可以通过多轮会话提问不同的问题,尽量全面覆盖模型的能力范围。
评测问题可以是答案固定的客观问题,或答案不固定的开放性、半开放性问题,对模型能力进行综合评测。
为了准确、全面、系统化地评估大语言模型的能力、向 Bot 开发者提供具备参考价值的模型榜单,扣子参考 Chatbot Arena 的评分机制,采用 Bradley-Terry 模型对模型进行满意度比较和全方位评测。
Bradley-Terry 模型类似 Elo 评分系统,是一种成熟的统计模型,适用于需要分析成对比较数据的情况,目前广泛用于体育比赛分析等领域。Bradley-Terry 模型假设每个参赛者都有一个固定的实力参数,比赛结果的概率由这些参数决定,通常使用 Logistic 函数来计算一支队伍相对于另一支队伍的胜率,可以更准确地估计模型之间的相对实力。
https://www.coze.cn/docs/guides/model_compete_overview
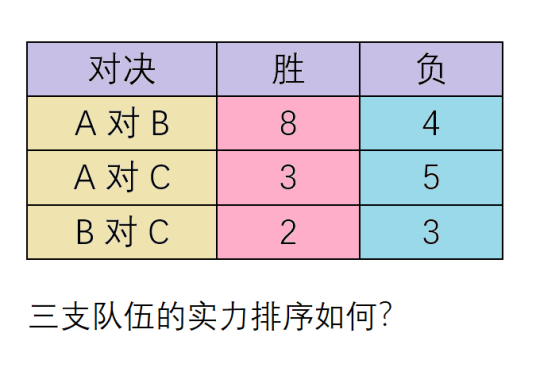
百度百科:Bradley-Terry 模型是一个体育比赛的统计模型,用几个参赛队(或运动员)两两竞技的胜负场次来估计每个参赛队的实力,进而预报任意两支参赛队交手时的胜负概率。
