

Continue是一个由硅谷YC支持的AI代码编程助手,提供VSCode和JetBrains插件,类似Github Copilot。Continue是开源的,而且支持Ollama,这意味着我们可以定制自己的AI编程助手。
GitHub:https://github.com/continuedev/continue
VSCode插件:https://marketplace.visualstudio.com/items?itemName=Continue.continue
JetBrains插件:https://plugins.jetbrains.com/plugin/22707-continue
也可以IDE的插件市场搜索 continue
下一步准备好Ollama的本地模型,官网https://ollama.com,下载后启动,在命令行执行
ollama run deepseek-coder:6.7b
在插件config.json中配置好模型参数
{ "models": [ { "title": "DeepSeek Coder 6.7B", "provider": "ollama", "model": "DeepSeek Coder 6.7B" } ], "tabAutocompleteModel": { "title": "DeepSeek Coder 6.7B", "provider": "ollama", "model": "deepseek-coder:6.7b-base" } }

Continue也支持利用 Ollama 运行多个模型和处理多个并发请求的能力,方法是使用DeepSeek Coder 6.7B进行自动完成,使用Llama 3 8B进行聊天。前提是你的机器足够强大。可以参考配置
{ "models": [ { "title": "Llama 3 8B", "provider": "ollama", "model": "Llama 3 8B" } ], "tabAutocompleteModel": { "title": "DeepSeek Coder 6.7B", "provider": "ollama", "model": "deepseek-coder:6.7b-base" } }
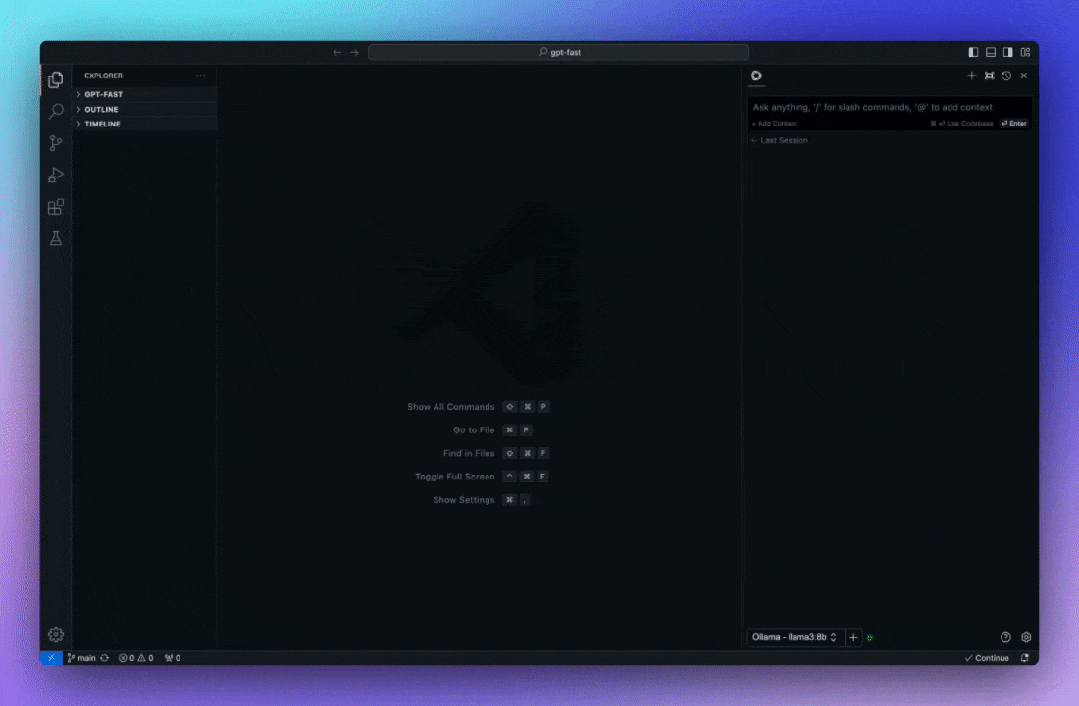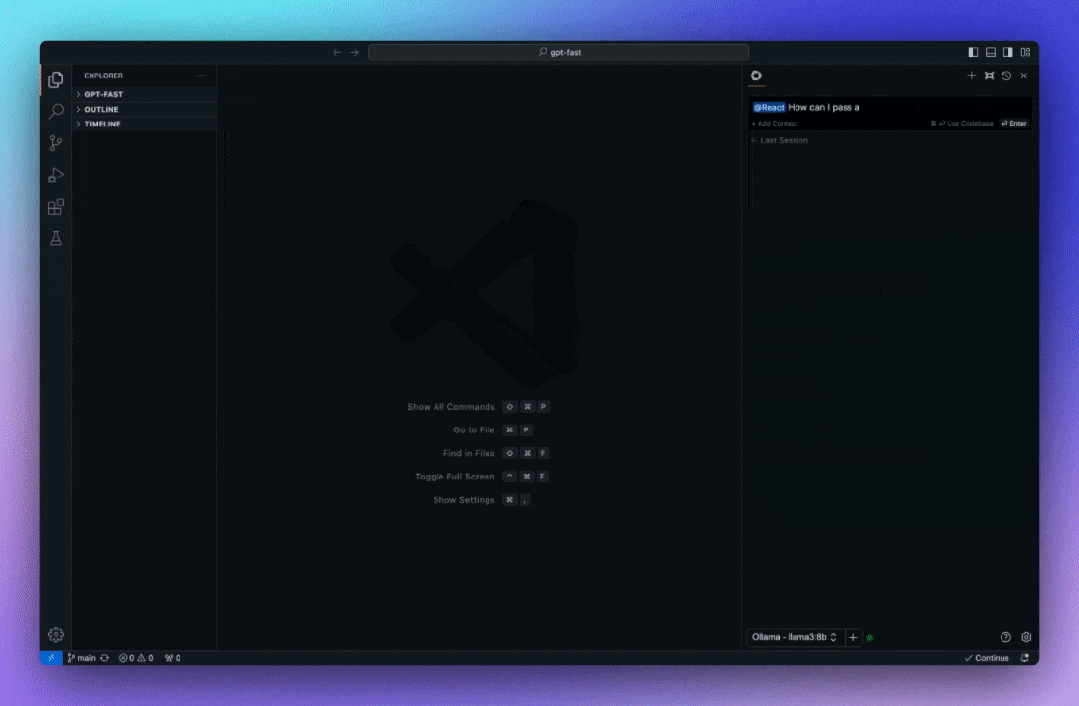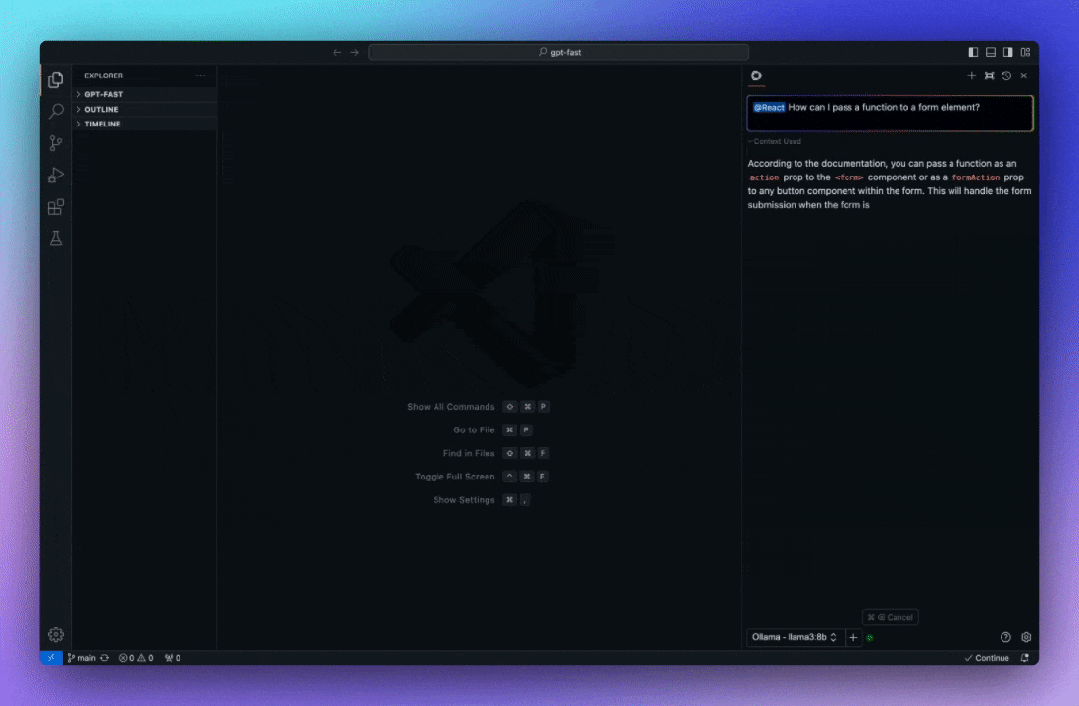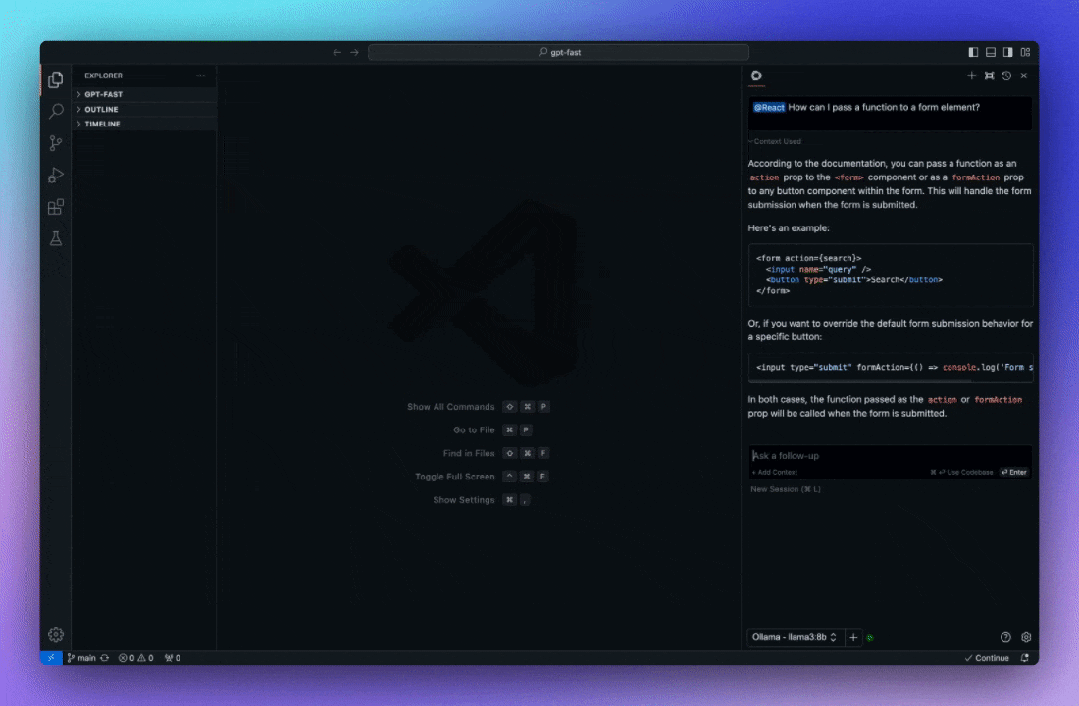
Continue 内置了@codebase上下文提供程序,可让自动从代码库中检索最相关的代码片段。假设已经设置了聊天模型(例如 Codestral、Llama 3),那么可以通过 Ollama 和LanceDB 的嵌入将整个体验保持在本地。建议使用nomic-embed-text嵌入。
ollama pull nomic-embed-text
然后配置config.json参数
{ "embeddingsProvider": { "provider": "ollama", "model": "nomic-embed-text" } }
根据代码库的大小,索引可能需要一些时间,然后可以直接提问,系统会自动找到重要的代码库部分并将其用于回答。
Continue 还内置了@docs上下文提供程序,可让您索引和检索来自任何文档站点的片段。假设您已经设置了聊天模型(例如 Codestral、Llama 3),您可以通过提供文档链接并提出问题以了解更多信息,从而让整个体验保持本地化。
@docs在聊天侧栏中输入内容,选择“添加文档”,复制并粘贴到 URL 字段中,然后在标题字段中输入查询的内容。
它应该快速索引已经上传的内容,然后你可以提出问题,它会自动找到重要部分并将其用于答案。
代码理解
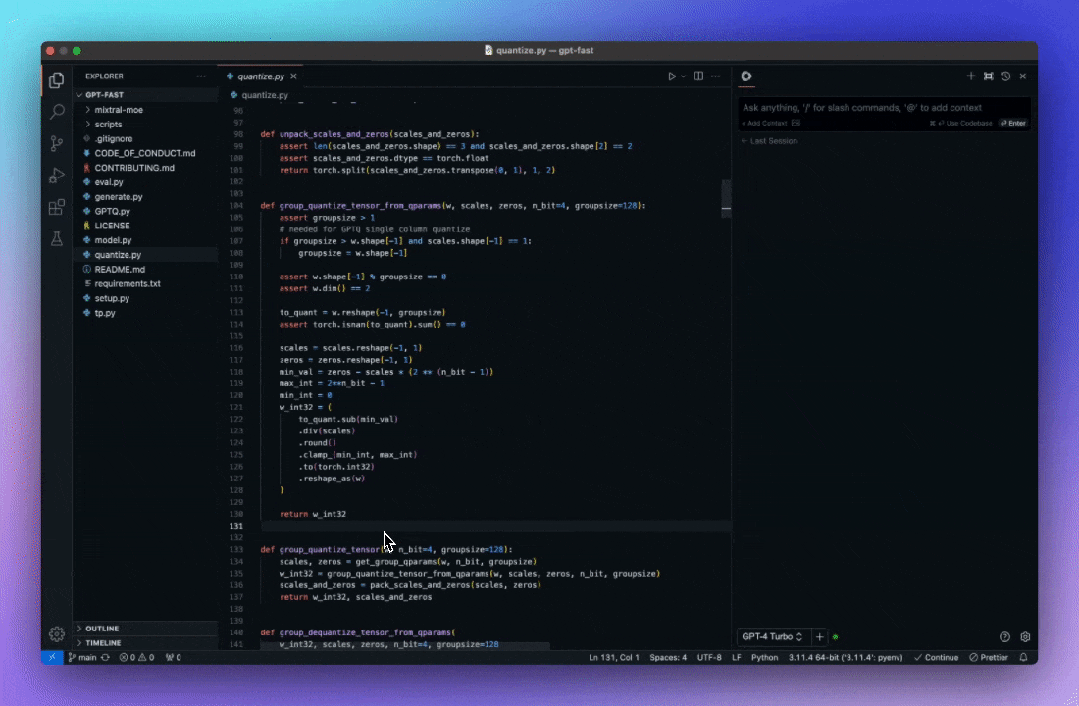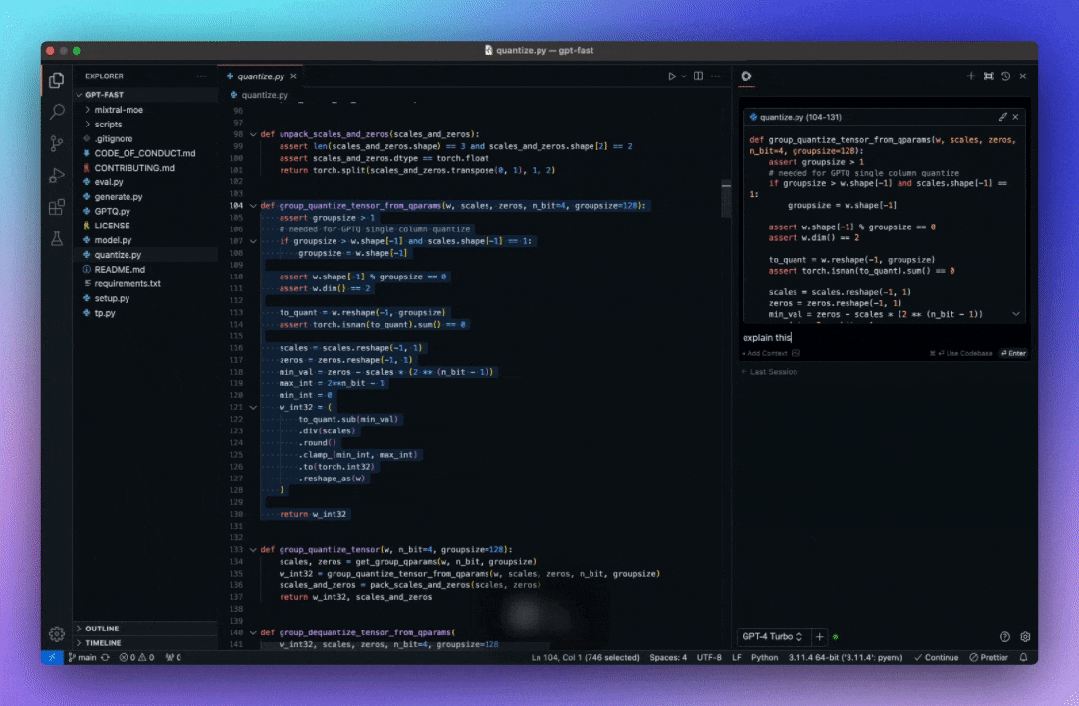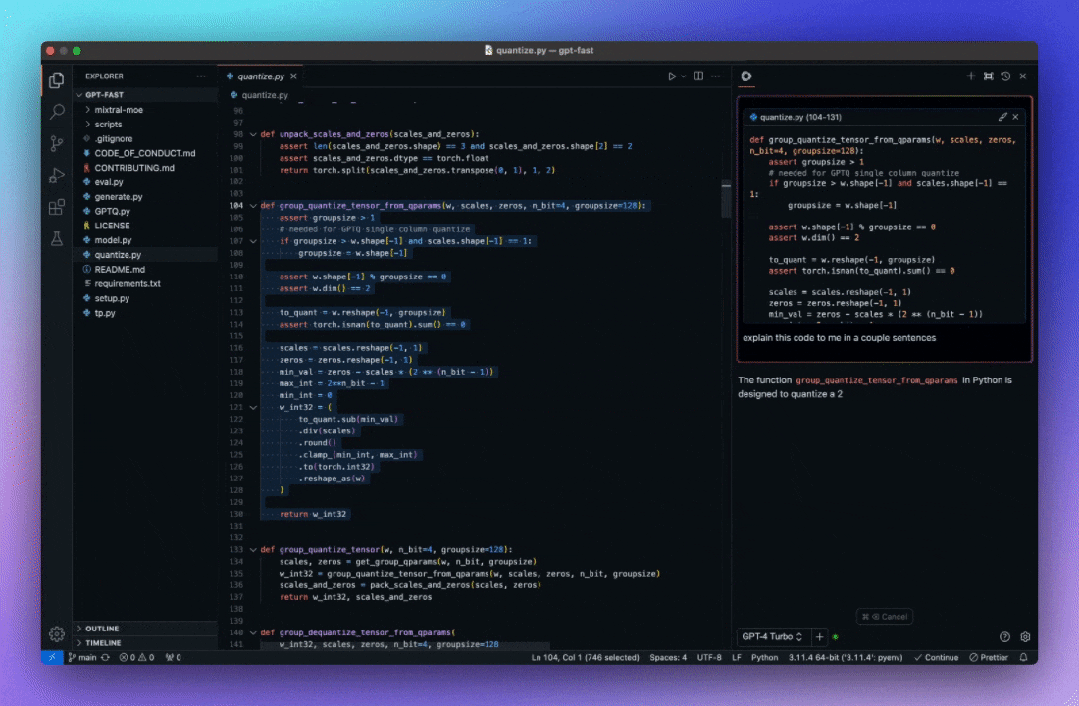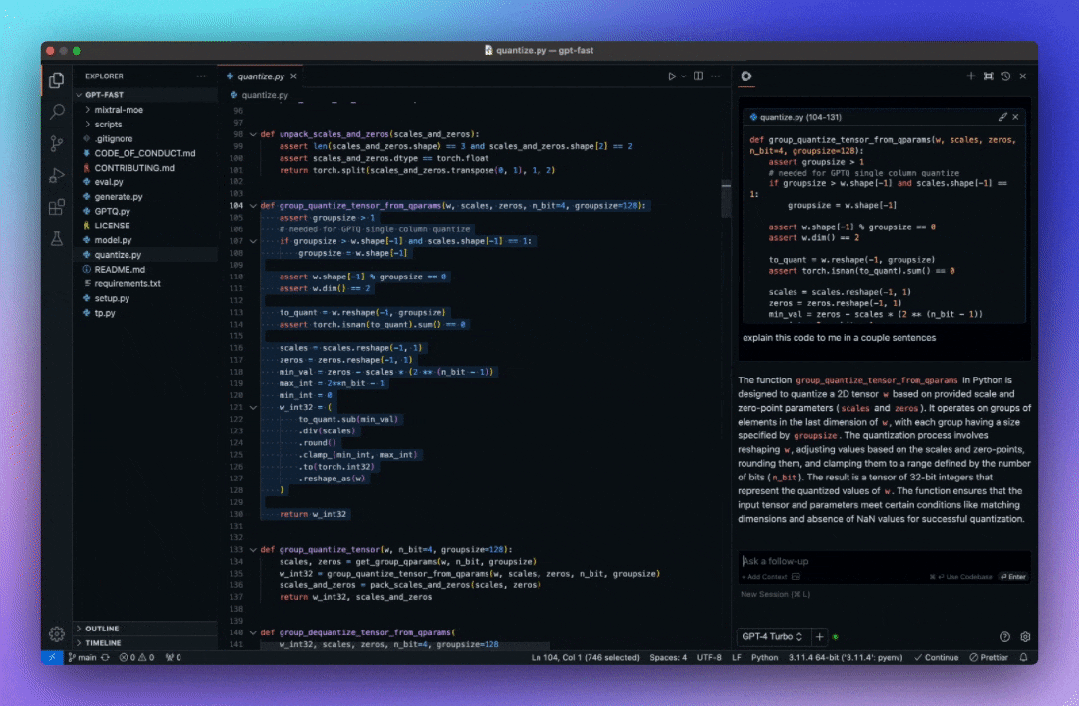
代码自动补全
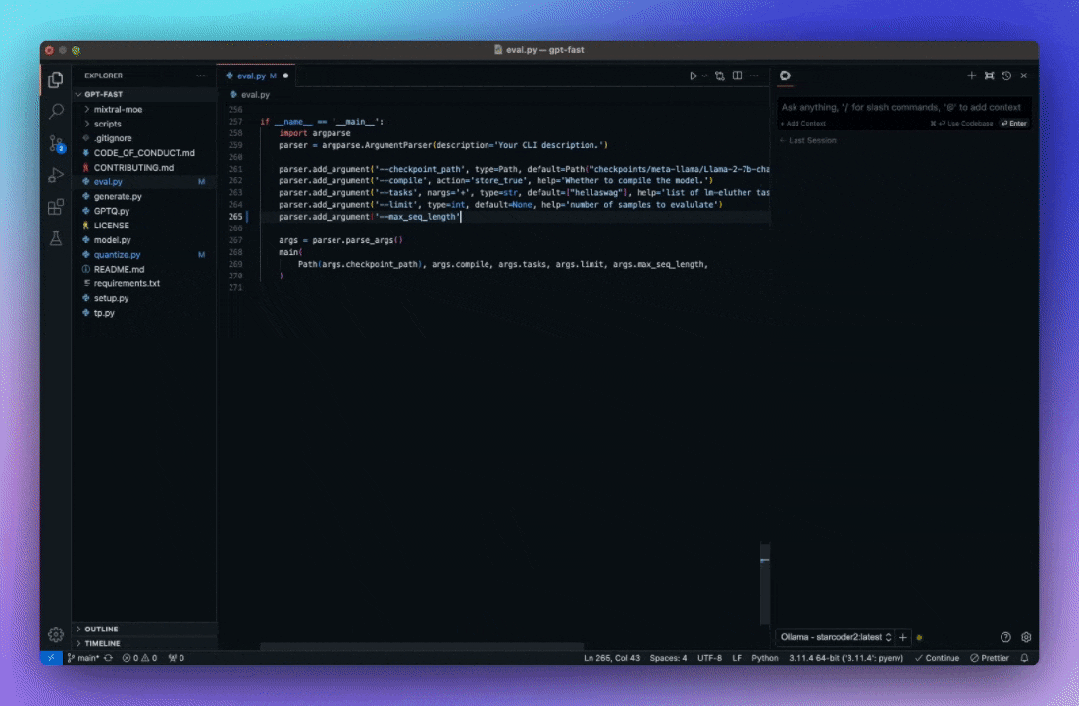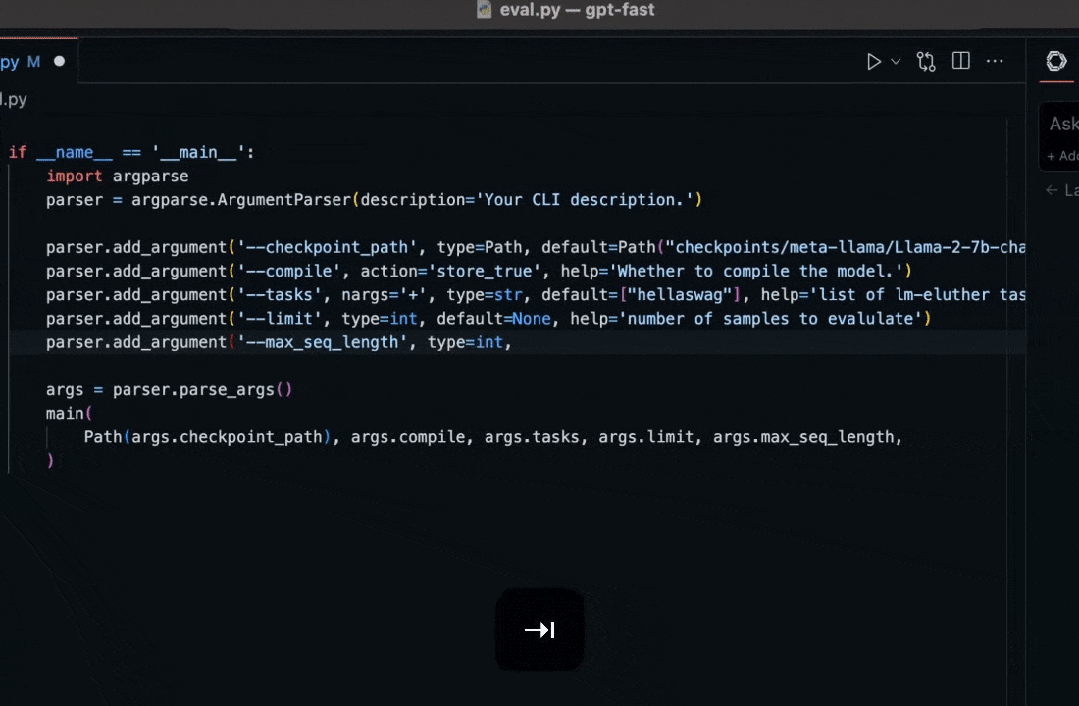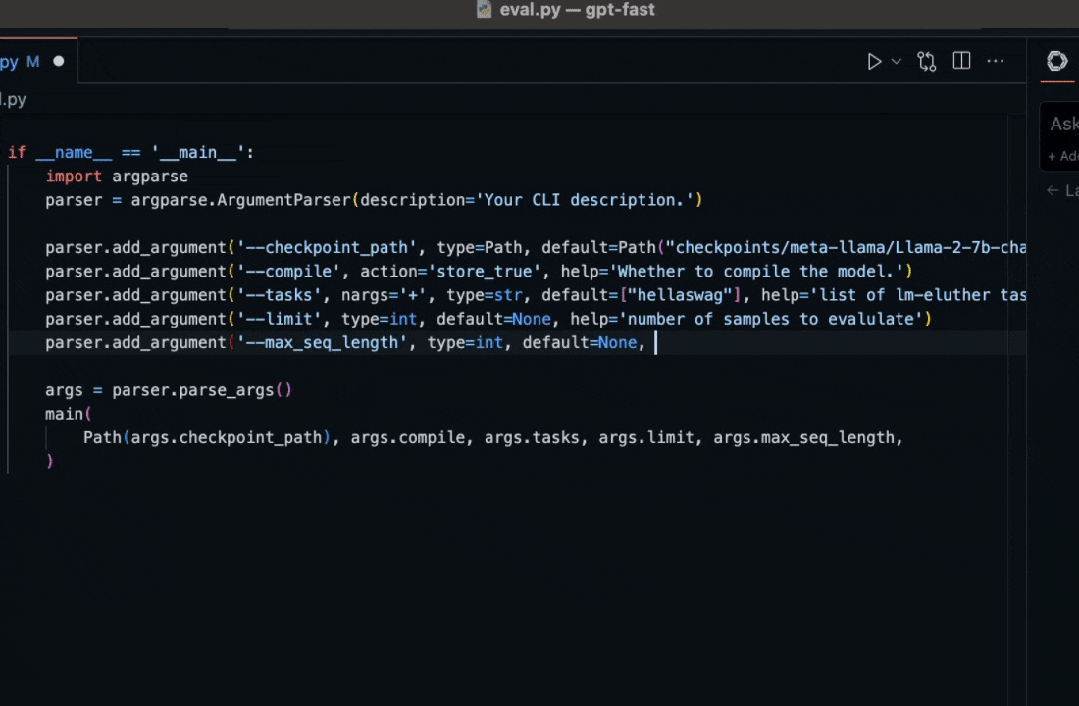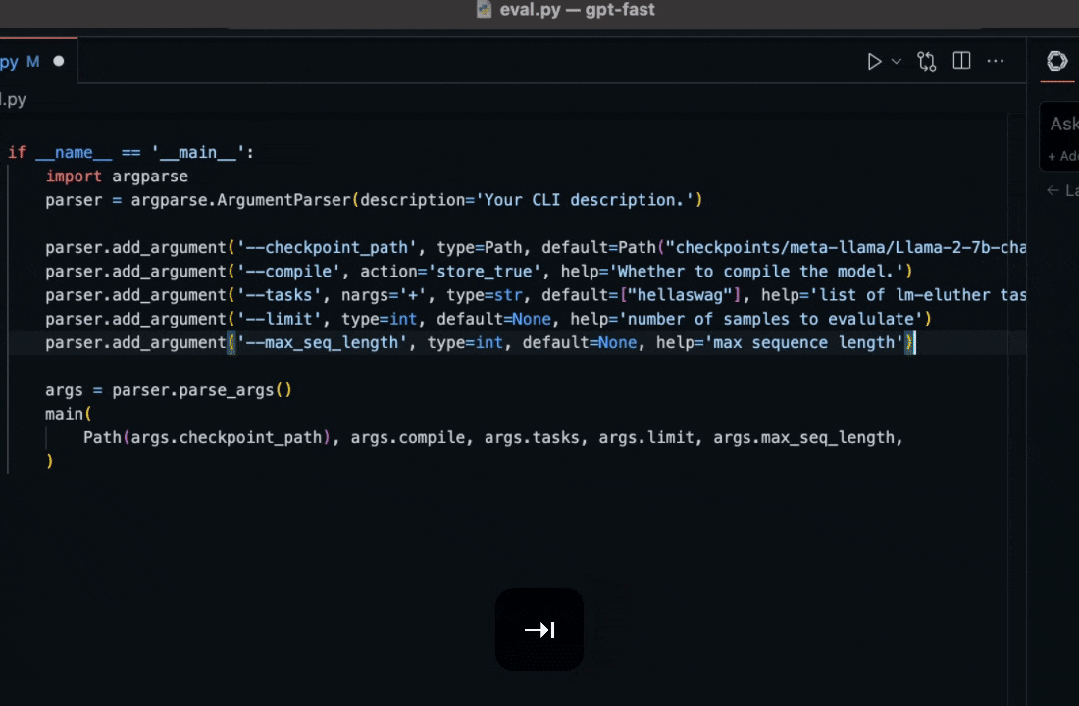
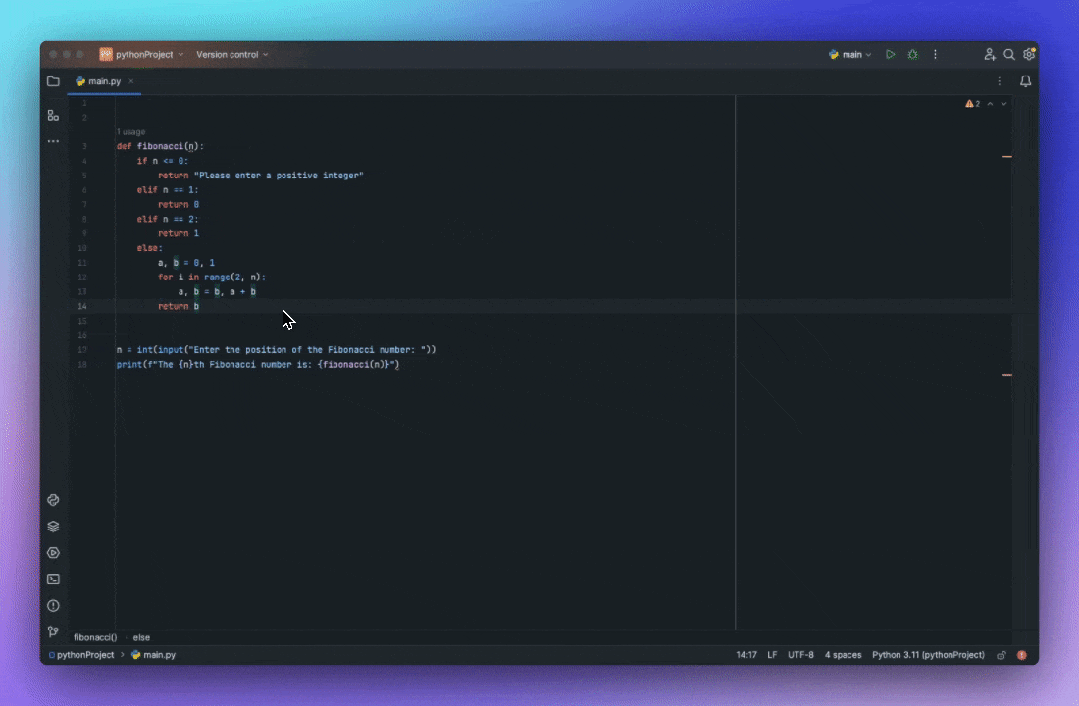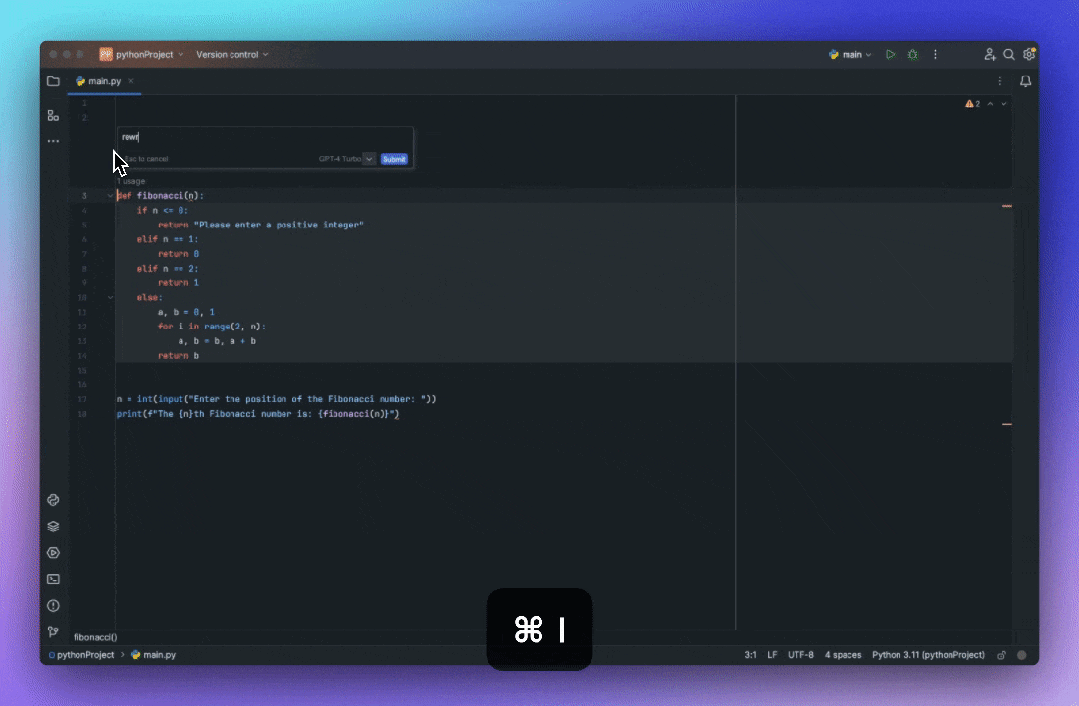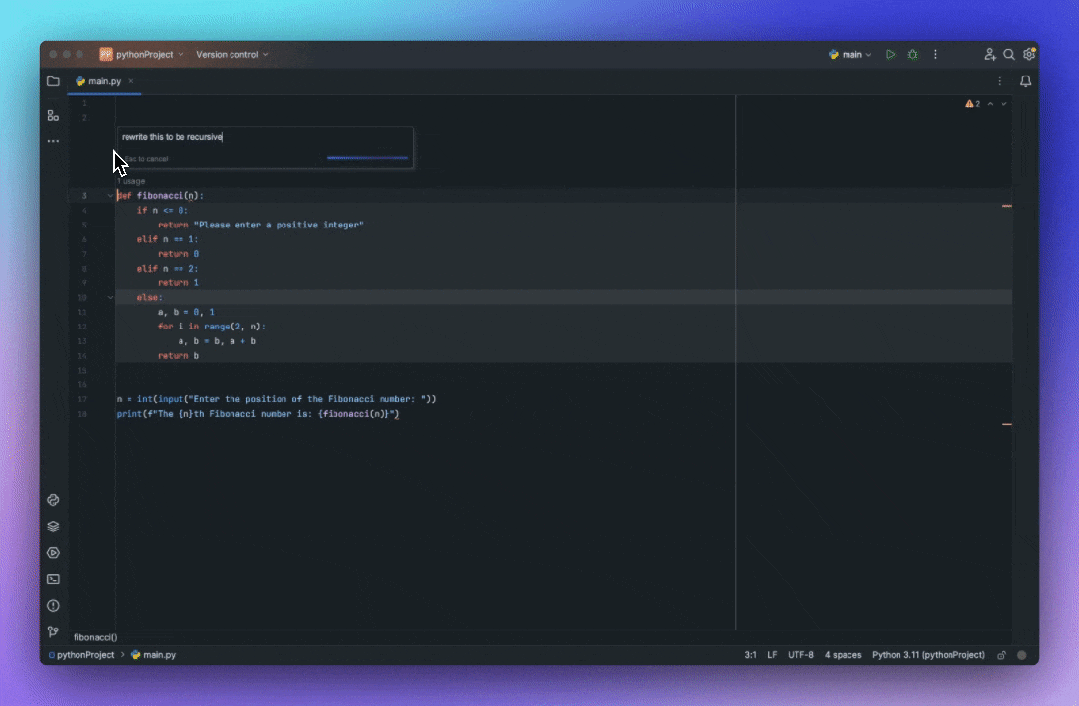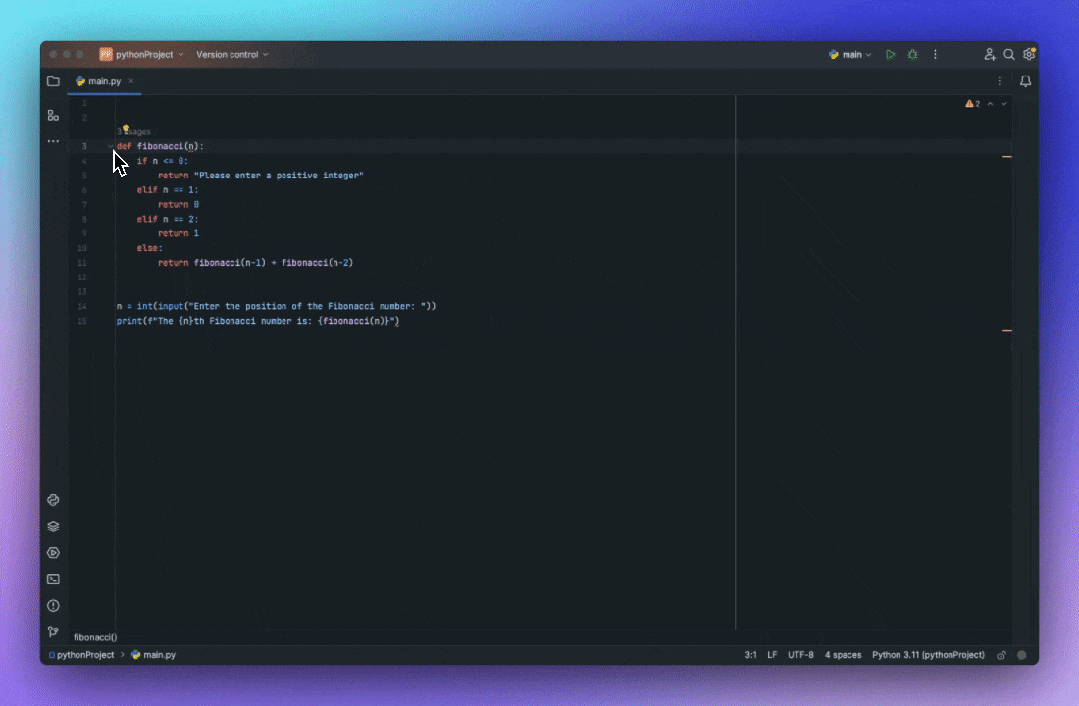
重写优化代码
查询代码库相关问题
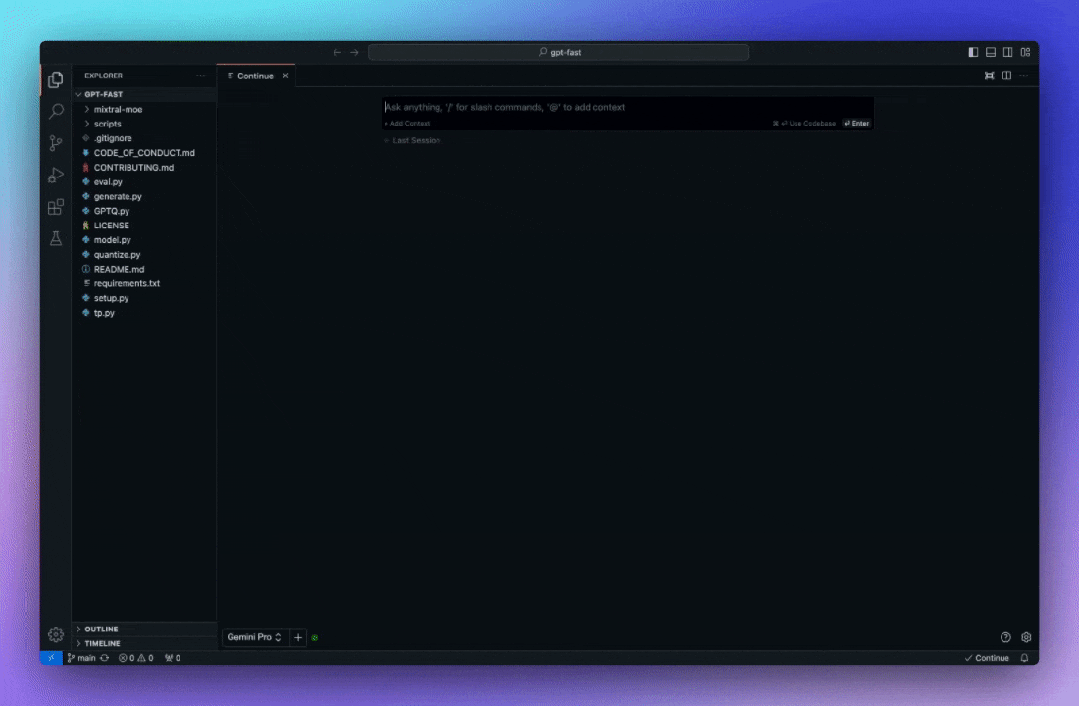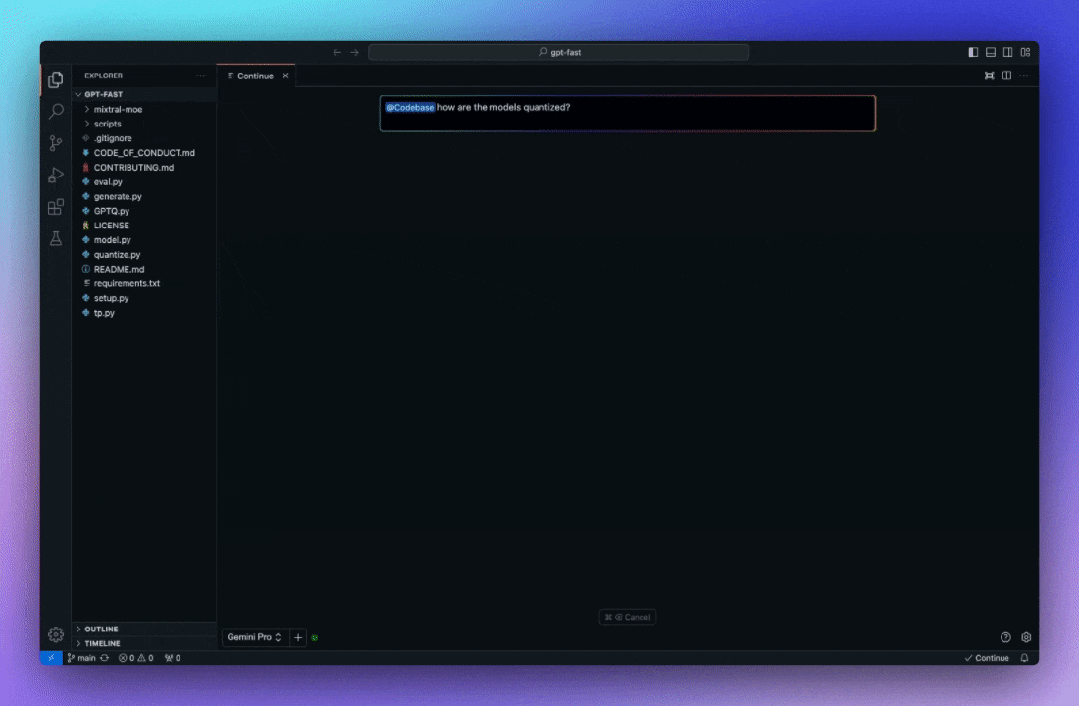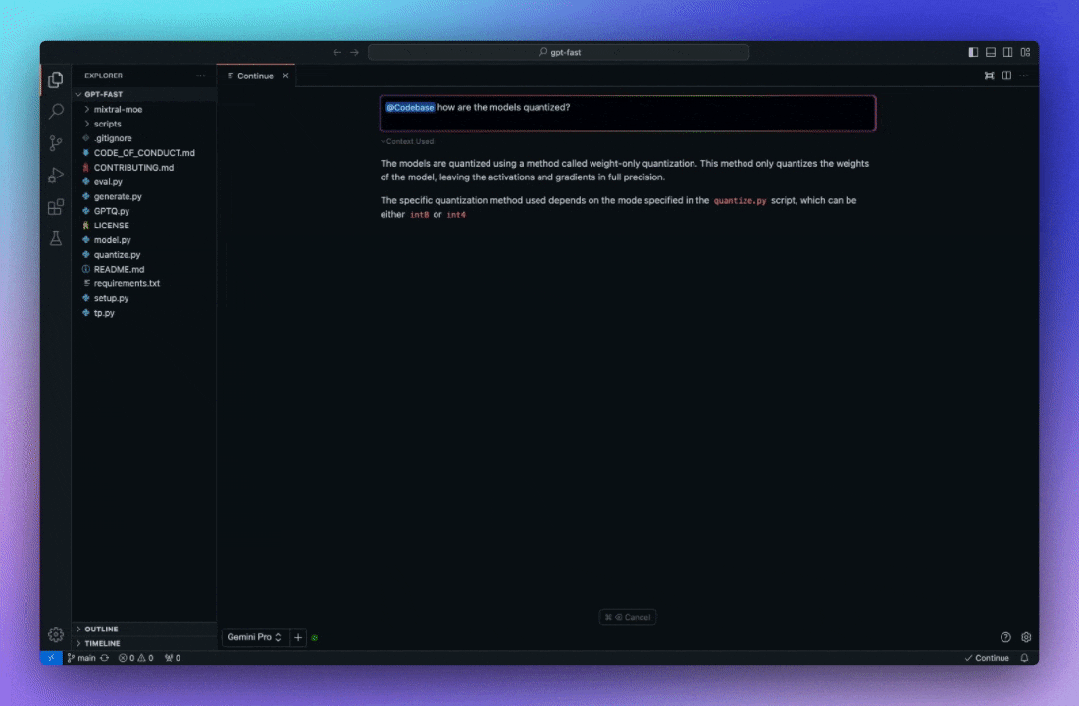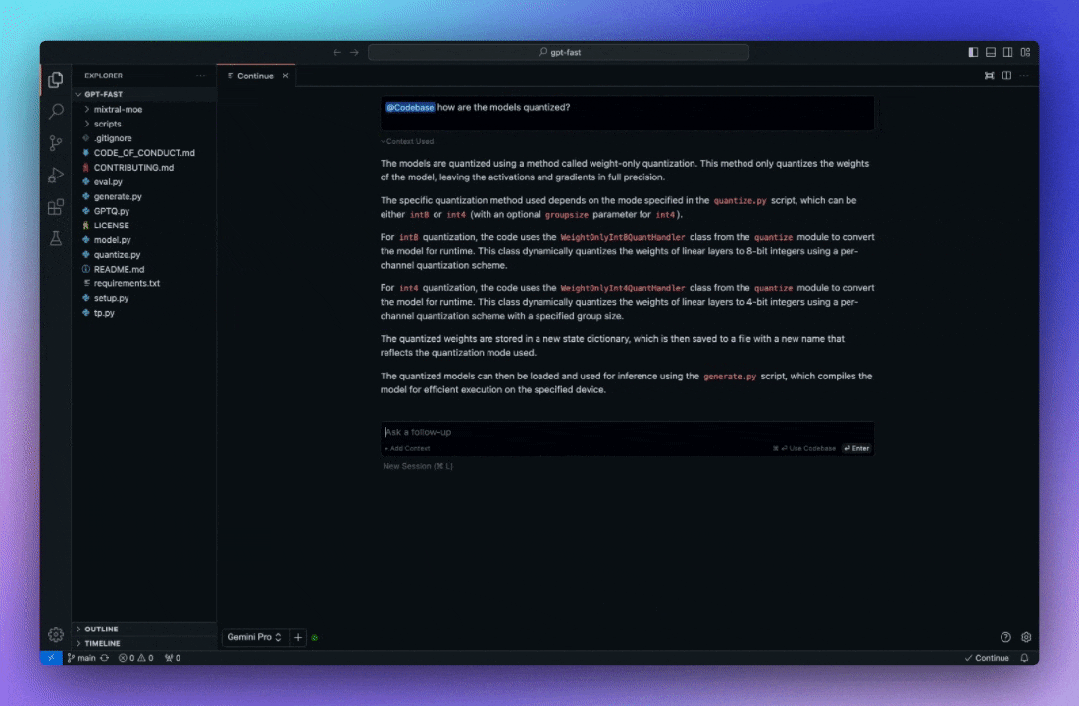
把文档作为上下文的问答
Ollama的资源要求
根据 Ollama.ai 官方文档,运行 Ollama 的建议系统要求是:
操作系统: Linux:Ubuntu 18.04 或更高版本,macOS:macOS 11 Big Sur 或更高版本
RAM: 8GB 用于运行 3B 模型,16GB 用于运行 7B 模型,32GB 用于运行 13B 模型
磁盘空间:12GB 用于安装 Ollama 和基本模型,存储模型数据所需的额外空间,具体取决于您使用的模型。
CPU: 建议使用至少 4 核的任何现代 CPU,对于运行 13B 模型,建议使用至少 8 核的 CPU。
GPU(可选): 运行 Ollama 不需要 GPU,但它可以提高性能,尤其是运行较大的模型。如果您有 GPU,可以使用它来加速 定制模型的训练。
除了上述内容之外,Ollama 还需要有效的互联网连接来下载基本模型并安装更新。
不同模型大小的内存(RAM)要求参考:
-
运行3B模型需要至少8GB的RAM。
-
运行7B模型需要至少8GB的RAM。
-
运行13B模型需要至少16GB的RAM。
-
运行33B模型需要至少32GB的RAM。
根据我自己的实际体验,MacBook M3 pro 18G,运行13B的模型会有点卡,运行7B的体验就很流畅。
